Quick Deployment
Notes
If you are new to Linkis, you can ignore this chapter, however, if you are already a Linkis user, we recommend you reading the following article before installing or upgrading: Brief introduction of the difference between Linkis1.0 and Linkis0.X.
Please note: Apart from the four EngineConnPlugins included in the Linkis1.0 installation package by default: Python/Shell/Hive/Spark. You can manually install other types of engines such as JDBC depending on your own needs. For details, please refer to EngineConnPlugin installation documents.
Engines that Linkis1.0 has adapted by default are listed below:
| Engine Type | Adaptation Situation | Included in official installation package |
|---|---|---|
| Python | Adapted in 1.0 | Included |
| JDBC | Adapted in 1.0 | Not Included |
| Shell | Adapted in 1.0 | Included |
| Hive | Adapted in 1.0 | Included |
| Spark | Adapted in 1.0 | Included |
| Pipeline | Adapted in 1.0 | Not Included |
| Presto | Not adapted in 1.0 | Not Included |
| ElasticSearch | Not adapted in 1.0 | Not Included |
| Impala | Not adapted in 1.0 | Not Included |
| MLSQL | Not adapted in 1.0 | Not Included |
| TiSpark | Not adapted in 1.0 | Not Included |
1. Determine your installation environment
The following is the dependency information for each engine.
| Engine Type | Dependency | Special Instructions |
|---|---|---|
| Python | Python Environment | If the path of logs and result sets are configured as hdfs://, then the HDFS environment is needed. |
| JDBC | No dependency | If the path of logs and result sets are configured as hdfs://, then the HDFS environment is needed. |
| Shell | No dependency | If the path of logs and result sets are configured as hdfs://, then the HDFS environment is needed. |
| Hive | Hadoop and Hive Environment | |
| Spark | Hadoop/Hive/Spark |
Requirement: At least 3G memory is required to install Linkis.
The default JVM heap memory of each microservice is 512M, and the heap memory of each microservice can be adjusted uniformly by modifying SERVER_HEAP_SIZE.If your computer resources are small, we suggest to modify this parameter to 128M. as follows:
vim ${LINKIS_HOME}/config/linkis-env.sh
# java application default jvm memory.
export SERVER_HEAP_SIZE="128M"
2. Linkis environment preparation
a. Fundamental software installation
The following softwares must be installed:
- MySQL (5.5+), How to install MySQL
- JDK (1.8.0_141 or higher) How to install JDK
b. Create user
For example: The deploy user is hadoop.
- Create a deploy user on the machine for installation.
sudo useradd hadoop
- Since the services of Linkis use sudo -u {linux-user} to switch engines to execute jobs, the deploy user should have sudo permission and do not need to enter the password.
vi /etc/sudoers
hadoop ALL=(ALL) NOPASSWD: NOPASSWD: ALL
Set the following global environment variables on each installation node so that Linkis can use Hadoop, Hive and Spark.
Modify the .bash_rc of the deploy user, the command is as follows:
vim /home/hadoop/.bash_rc ##Take the deploy user hadoop as an example.
The following is an example of setting environment variables:
#JDK
export JAVA_HOME=/nemo/jdk1.8.0_141
##If you do not use Hive, Spark or other engines and do not rely on Hadoop as well,then there is no need to modify the following environment variables.
#HADOOP
export HADOOP_HOME=/appcom/Install/hadoop
export HADOOP_CONF_DIR=/appcom/config/hadoop-config
#Hive
export HIVE_HOME=/appcom/Install/hive
export HIVE_CONF_DIR=/appcom/config/hive-config
#Spark
export SPARK_HOME=/appcom/Install/spark
export SPARK_CONF_DIR=/appcom/config/spark-config/spark-submit
export PYSPARK_ALLOW_INSECURE_GATEWAY=1 # Parameters must be added to Pyspark
- If you want to equip your Pyspark and Python with drawing functions, you need to install the drawing module on each installation node. The command is as follows:
python -m pip install matplotlib
c. Preparing installation package
Download the latest installation package from the Linkis release. (Click here to enter the download page)
Decompress the installation package to the installation directory and modify the configuration of the decompressed file.
tar -xvf wedatasphere-linkis-x.x.x-combined-package-dist.tar.gz
d. Basic configuration modification(Do not rely on HDFS)
vi config/linkis-env.sh
#SSH_PORT=22 #Specify SSH port. No need to configuer if the stand-alone version is installed
deployUser=hadoop #Specify deploy user
LINKIS_HOME=/appcom/Install/Linkis # Specify installation directory.
WORKSPACE_USER_ROOT_PATH=file:///tmp/hadoop # Specify user root directory. Generally used to store user's script and log files, it's user's workspace.
RESULT_SET_ROOT_PATH=file:///tmp/linkis # The result set file path, used to store the result set files of the Job.
ENGINECONN_ROOT_PATH=/appcom/tmp #Store the installation path of ECP. A local directory where deploy user has write permission.
ENTRANCE_CONFIG_LOG_PATH=file:///tmp/linkis/ #Entrance's log path
## LDAP configuration. Linkis only supports deploy user login by default, you need to configure the following parameters to support multi-user login.
#LDAP_URL=ldap://localhost:1389/
#LDAP_BASEDN=dc=webank,dc=com
e. Basic configuration modification(Rely on HDFS/Hive/Spark)
vi config/linkis-env.sh
SSH_PORT=22 #Specify SSH port. No need to configuer if the stand-alone version is installed
deployUser=hadoop #Specify deploy user
WORKSPACE_USER_ROOT_PATH=file:///tmp/hadoop #Specify user root directory. Generally used to store user's script and log files, it's user's workspace.
RESULT_SET_ROOT_PATH=hdfs:///tmp/linkis # The result set file path, used to store the result set files of the Job.
ENGINECONN_ROOT_PATH=/appcom/tmp #Store the installation path of ECP. A local directory where deploy user has write permission.
ENTRANCE_CONFIG_LOG_PATH=hdfs:///tmp/linkis/ #Entrance's log path
#1.0 supports multi-Yarn clusters, therefore, YARN_RESTFUL_URL must be configured
YARN_RESTFUL_URL=http://127.0.0.1:8088 #URL of Yarn's ResourceManager
# If you want to use it with Scriptis, for CDH version of hive, you need to set the following parameters.(For the community version of Hive, you can leave out the following configuration.)
HIVE_META_URL=jdbc://... #URL of Hive metadata database
HIVE_META_USER= # username of the Hive metadata database
HIVE_META_PASSWORD= # password of the Hive metadata database
# set the conf directory of hadoop/hive/spark
HADOOP_CONF_DIR=/appcom/config/hadoop-config #hadoop's conf directory
HIVE_CONF_DIR=/appcom/config/hive-config #hive's conf directory
SPARK_CONF_DIR=/appcom/config/spark-config #spark's conf directory
## LDAP configuration. Linkis only supports deploy user login by default, you need to configure the following parameters to support multi-user login.
#LDAP_URL=ldap://localhost:1389/
#LDAP_BASEDN=dc=webank,dc=com
##If your spark version is not 2.4.3, you need to modify the following parameter:
#SPARK_VERSION=3.1.1
##:If your hive version is not 1.2.1, you need to modify the following parameter:
#HIVE_VERSION=2.3.3
f. Modify the database configuration
vi config/db.sh
# set the connection information of the database
# including ip address, database's name, username and port
# Mainly used to store user's customized variables, configuration parameters, UDFs, and samll functions, and to provide underlying storage of the JobHistory.
MYSQL_HOST=
MYSQL_PORT=
MYSQL_DB=
MYSQL_USER=
MYSQL_PASSWORD=
3. Installation and Startup
1. Execute the installation script:
sh bin/install.sh
2. Installation steps
- The install.sh script will ask you whether to initialize the database and import the metadata.
It is possible that a user might repeatedly run the install.sh script and results in clearing all data in databases. Therefore, each time the install.sh is executed, user will be asked if they need to initialize the database and import the metadata.
Please select yes on the first installation.
Please note: If you are upgrading the existing environment of Linkis from 0.X to 1.0, please do not choose yes directly, refer to Linkis1.0 Upgrade Guide first.
3. Whether install successfully
You can check whether the installation is successful or not by viewing the logs printed on the console.
If there is an error message, check the specific reason for that error or refer to FAQ for help.
4. Linkis quick startup
(1). Start services
Run the following commands on the installation directory to start all services.
sh sbin/linkis-start-all.sh
(2). Check if start successfully
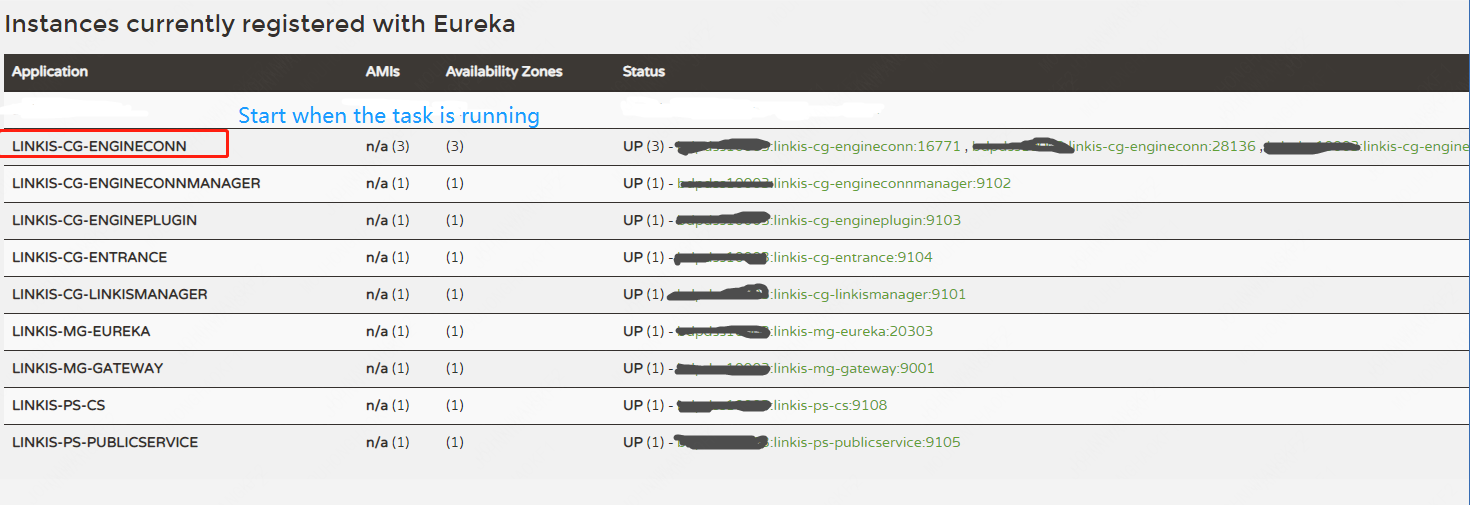
You can check the startup status of the services on the Eureka, here is the way to check:
Open http://${EUREKA_INSTALL_IP}:${EUREKA_PORT} on the browser and check if services have registered successfully.
If you have not specified EUREKA_INSTALL_IP and EUREKA_INSTALL_IP in config.sh, then the HTTP address is http://127.0.0.1:20303
As shown in the figure below, if all of the following micro-services are registered on theEureka, it means that they've started successfully and are able to work.