CS Cache Architecture
CSCache Architecture
issues that need resolving
1.1. Memory structure needs to be solved:
Support splitting by ContextType: speed up storage and query performance
Support splitting according to different ContextID: Need to complete ContextID, see metadata isolation
Support LRU: Recycle according to specific algorithm
Support searching by keywords: Support indexing by keywords
Support indexing: support indexing directly through ContextKey
Support traversal: need to support traversal according to ContextID and ContextType
1.2 Loading and parsing problems to be solved:
Support parsing ContextValue into memory data structure: It is necessary to complete the parsing of ContextKey and value to find the corresponding keywords.
Need to interface with the Persistence module to complete the loading and analysis of the ContextID content
1.3 Metric and cleaning mechanism need to solve the problem:
When JVM memory is not enough, it can be cleaned based on memory usage and frequency of use
Support statistics on the memory usage of each ContextID
Support statistics on the frequency of use of each ContextID
ContextCache Architecture
The architecture of ContextCache is shown in the following figure:
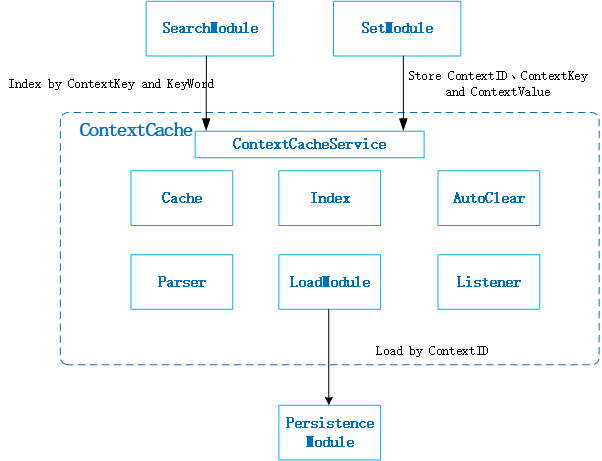
ContextService: complete the provision of external interfaces, including additions, deletions, and changes;
Cache: complete the storage of context information, map storage through ContextKey and ContextValue
Index: The established keyword index, which stores the mapping between the keywords of the context information and the ContextKey;
Parser: complete the keyword analysis of the context information;
LoadModule completes the loading of information from the persistence layer when the ContextCache does not have the corresponding ContextID information;
AutoClear: When the Jvm memory is insufficient, complete the on-demand cleaning of ContextCache;
Listener: Metric information for the mobile phone ContextCache, such as memory usage and access times.
ContextCache storage structure design
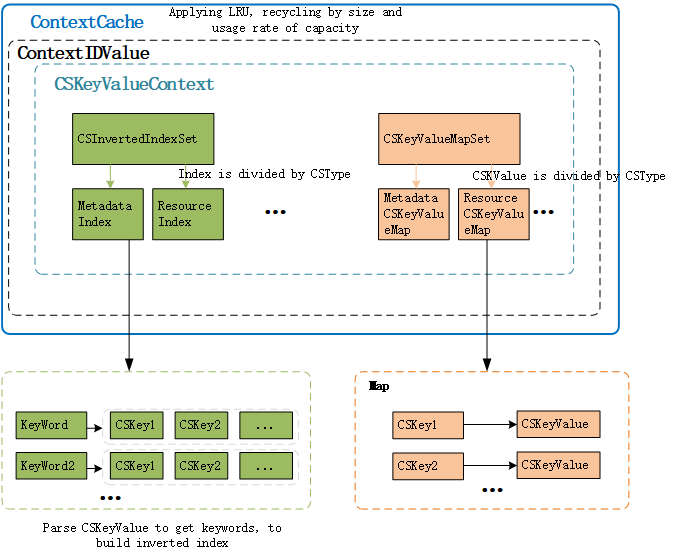
The storage structure of ContextCache is divided into three layers:
ContextCache: stores the mapping relationship between ContextID and ContextIDValue, and can complete the recovery of ContextID according to the LRU algorithm;
ContextIDValue: CSKeyValueContext that has stored all context information and indexes of ContextID. And count the memory and usage records of ContestID.
CSKeyValueContext: Contains the CSInvertedIndexSet index set that stores and supports keywords according to type, and also contains the storage set CSKeyValueMapSet that stores ContextKey and ContextValue.
CSInvertedIndexSet: categorize and store keyword indexes through CSType
CSKeyValueMapSet: categorize and store context information through CSType
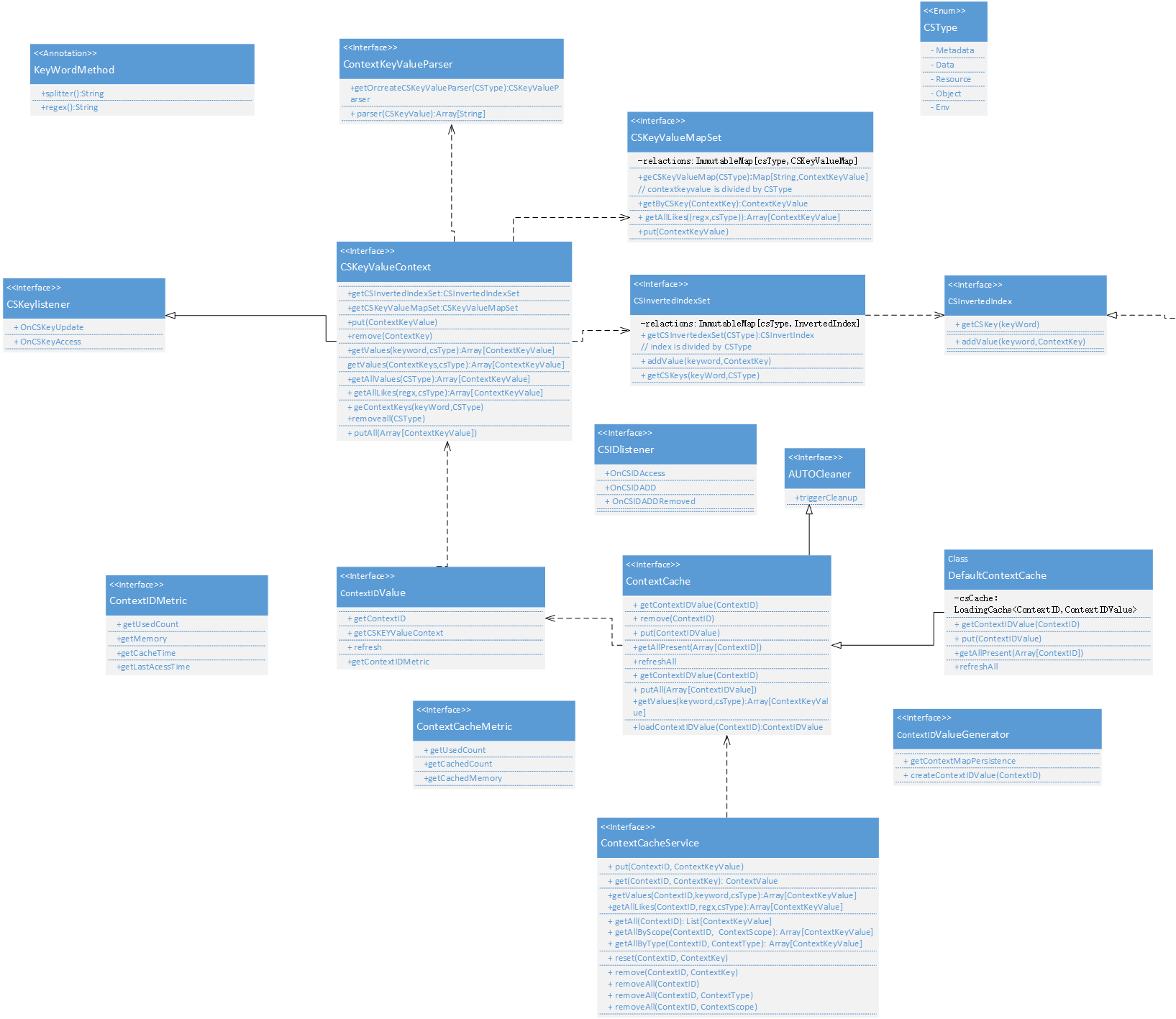
ContextCache UML Class Diagram Design
ContextCache Timing Diagram
The following figure draws the overall process of using ContextID, KeyWord, and ContextType to check the corresponding ContextKeyValue in ContextCache.
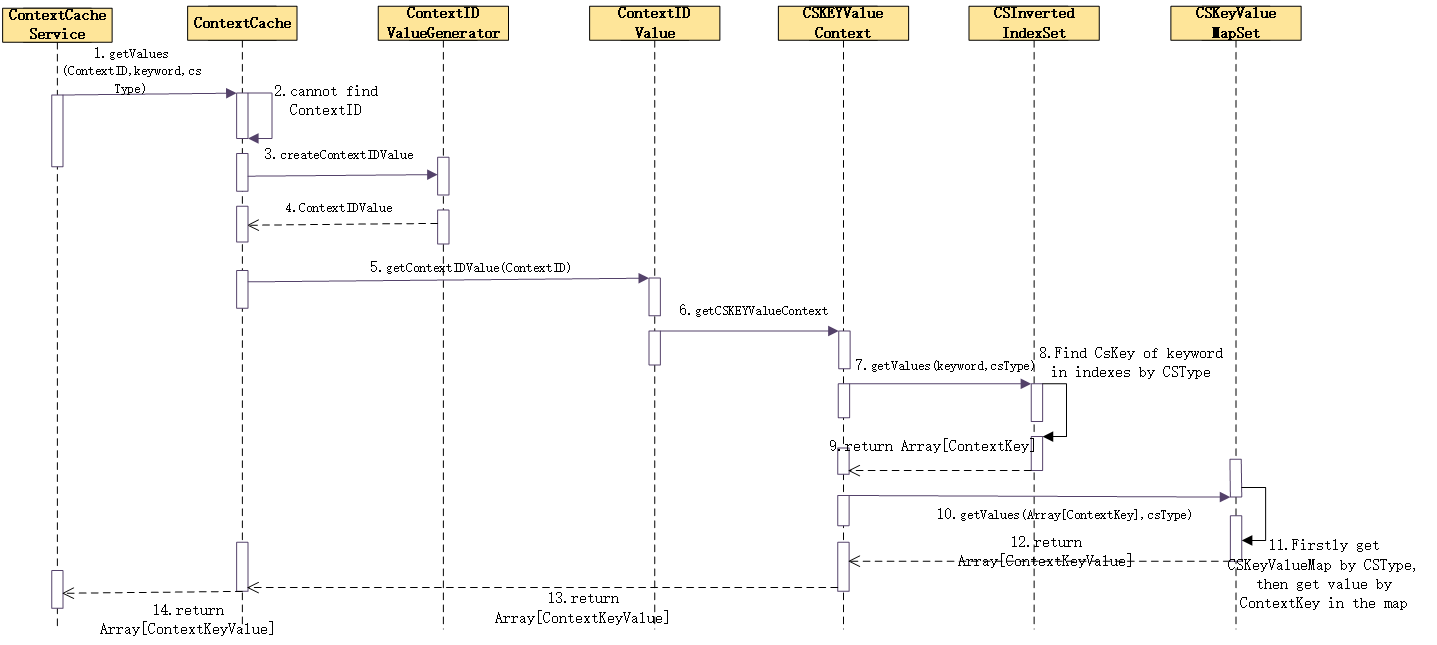
Note: The ContextIDValueGenerator will go to the persistence layer to pull the Array[ContextKeyValue] of the ContextID, and parse the ContextKeyValue key storage index and content through ContextKeyValueParser.
The other interface processes provided by ContextCacheService are similar, so I won't repeat them here.
KeyWord parsing logic
The specific entity bean of ContextValue needs to use the annotation \@keywordMethod on the corresponding get method that can be used as the keyword. For example, the getTableName method of Table must be annotated with \@keywordMethod.

When ContextKeyValueParser parses ContextKeyValue, it scans all the annotations modified by KeywordMethod of the specific object passed in and calls the get method to obtain the returned object toString, which will be parsed through user-selectable rules and stored in the keyword collection. Rules have separators, and regular expressions
Precautions:
The annotation will be defined to the core module of cs
The modified Get method cannot take parameters
The toSting method of the return object of the Get method must return the keyword