Overview
The team needs to use SQL and Python syntax to analyze the data at the same time on the page. During the investigation, I found that Linkis can meet the needs. As a Huawei MRS is used, it is different from the open source software. It also carried out secondary development and adaptation. This article will share the experience, hoping to help students in need.
environment and version
- JDK-1.8.0_112, Maven-3.5.2
- Hadoop-3.1.1, spark-3.1.1, hive-3.1.0, zookerper-3.5.9 (Huawei MRS version)
- Linkis-1.3.0
- Scriptis-Web 1.1.0
dependence adjustment and packaging
First download the source code of 1.3.0 from the Linkis official website, and then adjust the dependent version
Linkis outermost adjustment pom file
<hadoop.version>3.1.1</hadoop.version>
<zookerper.version>3.5.9</zookerper.version>
<curaor.version>4.2.0</curaor.version>
<guava.version>30.0-jre</guava.version>
<json4s.version>3.7.0-M5</json4s.version>
<scala.version>2.12.15</scala.version>
<scala.binary.version>2.12</scala.binary.version>
linkis-engineplugin-hive的pom文件
<hive.version>3.1.2</hive.version>
linkis-engineplugin-spark的pom文件
<spark.version>3.1.1</spark.version>
linkis-hadoop-common的pom文件
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId> <!-Just replace the line and replace it with <Arttifactid> Hadoop-HDFS-Client </Artifactid>->->
<version>${hadoop.version}</version>
</dependency>
Modify the Hadoop-HDFS to:
<dependency>
<cepid> org.apache.hadoop </groupid>
<Artifactid> Hadoop-HDFS-Client </Artifactid>
<Version> $ {Hadoop.Version} </version>
</dependency>
Linkis-Label-Common
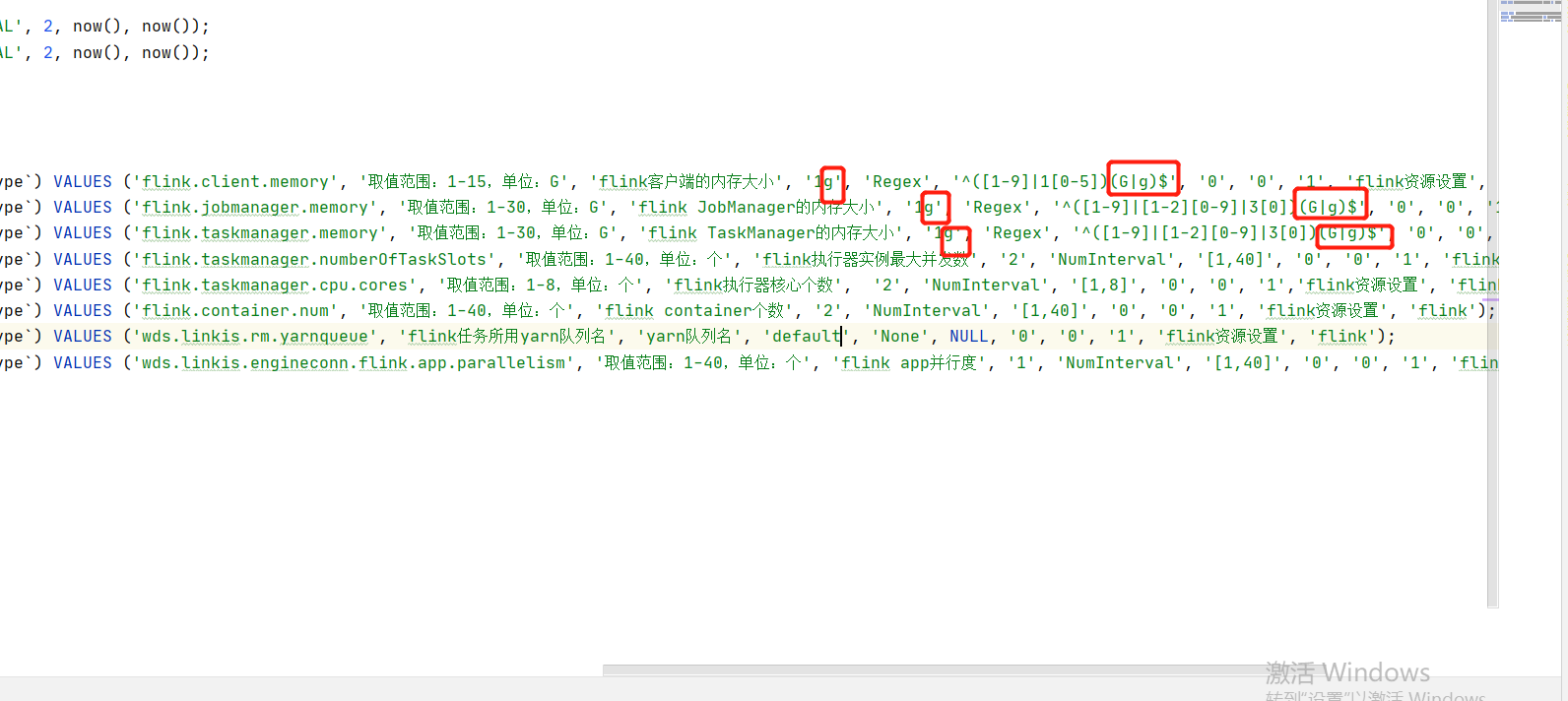
org.apache.linkis.manager.label.conf.labelcommonconfig Modify the default version, which is convenient for subsequent self -compiling scheduling components
Public Static Final Commonvars <string> Spark_engine_Version =
Commonvars.apply ("wds.linkis.spark.engine.version", "3.1.1");
Public Static Final Commonvars <string> Hive_engine_Version =
Commonvars.apply ("wds.linkis.hive.engine.version", "3.1.2");
Linkis-computation-Governance-Common
org.apache.linkis.governance.Common.conf.governanceCommonConf Modify the default version, which is convenient for subsequent self -compiling scheduling components
Val spark_engine_version = Commonvars ("wds.linkis.spark.engine.version", "3.1.1")
VAL HIVE_ENGINE_VERSION = Commonvars ("wds.linkis.hive.engine.version", "3.1.2")
Compilation
After the above configuration is adjusted, you can start compiling full amount, and execute the following commands in turn
cd linkis-x.x.x
MVN -N Install
MVN CLEAN Install -DSKIPTESTS
Compile Error
-If when you compile it, there is an error, try to enter a module alone to compile, see if there are errors, and adjust according to specific errors -Since the SCALA language is used in Linkis for code writing, it is recommended that you can configure the SCALA environment first to facilitate reading the source code -Aar package conflict is the most common problem, especially after upgrading Hadoop, please adjust the dependent version patiently
DatasphereStudio pom file
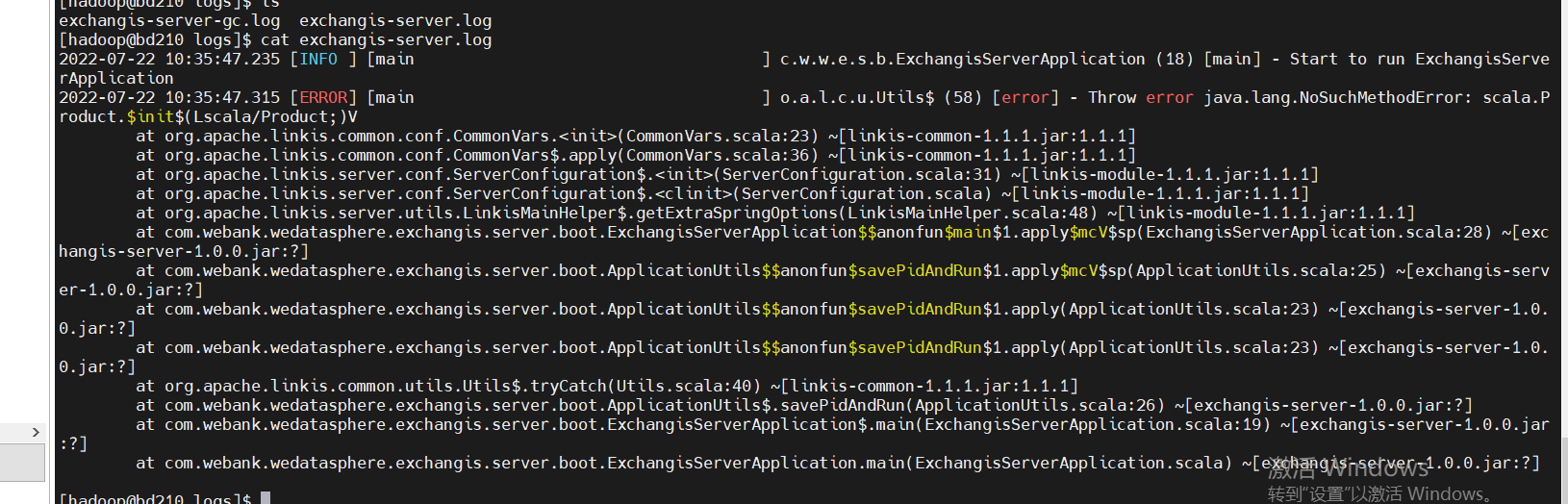
As we upgrade the version of Scala, the error will be reported when deploying. Conn to BML Now Exit Java.net.socketexception: Connection Reset. Here you need to modify the SCALA version and re -compile.
- Delete the low version of the DSS-Gateway-SUPPPPORT JAR package,
- Modify the scala version in DSS 1.1.0 to 2.12, compile it, get the new DSS-Gateway-SUPPPORT -.1.0.JAR, replace the linkis_installhome/lib/linkis-spaint-service/linkis-mg-gateway The original jar package of the Central Plains
<!-The SCALA environment is consistent->
<scala.version> 2.12.15 </scala.version>
According to the adjustment of the dependent version above, you can solve most of the problems. If you have any problems, you need to carefully adjust the corresponding log. If a complete package can be compiled, it represents the full compilation of Linkis and can be deployed.
deployment
- In in order to allow the engine node to have sufficient resource execution script, we have adopted multiple server deployments, and the general deployment structure is as follows. -SLB 1 load balancing is rotary inquiry -E ECS-WEB 2 Nginx, static resource deployment, background agent forwarding -ECS-APP 2 micro-service governance, computing governance, public enhancement and other node deployment -ECS-APP 4 Engineconnmanager node deployment
linkis deployment
- At the use of multiple node deployments, we did not peel the code, or put the full amount on the server, but just modified the startup script to make it only start the service required
Refer to the official website single machine deployment example: https: //linkis.apache.org/zh-docs/1.3.0/dePlayment/dePlay-qick
Linkis Deployment Points Attention Point
- Deployment user: The startup user of the core process of Linkis. At the same time, this user will default as an administrator permissions. During the deployment process, the corresponding administrator login password, located in the linkis support specified in CONF/LINKIS-MG-Gateway.properties file file Submitted and executed users. The main process service of Linkis will be switched to the corresponding user through the SUDO -U $ {linkis-user}, and then executes the corresponding engine startup command, so the user of the engine linkis -ngine processes is the executor of the task. -The user defaults to the submission and executor of the task, if you want to change to the login user, you need to modify org.apache.linkis.entRance.Restful.entRANCERESTFAPI class json.put (taskConstant.execute_user, moduleuseuserutills.GetOperationUser (REQ)); json.put (taskConstant.submit_user, SecurityFilter.getLoginusername (REQ)); Change the above settings to the user and execute user to the Scriptis page to log in to the user
- Sudo -U $ {linkis -user} Switch to the corresponding user. If you use the login user, this command may fail, and you need to modify the command here.
- org.apache.linkis.ecm.server.operator.EngineConnYarnLogOperator.sudoCommands
private def sudoCommands(creator: String, command: String): Array[String] = {
Array(
"/bin/bash",
"-c",
"sudo su " + creator + " -c \"source ~/.bashrc 2>/dev/null; " + command + "\""
)
} change into
private def sudoCommands(creator: String, command: String): Array[String] = {
Array(
"/bin/bash",
"-c",
"\"source ~/.bashrc 2>/dev/null; " + command + "\""
)
}
- Mysql's driver package must be Copy to/lib/linkis-commons/public-module/and/lib/linkis-spring-cloud-services/linkis-mg-gateway/
- The default is to use static users and passwords. Static users are deploying users. Static passwords will generate a password string in execution deployment, stored at $ {linkis_home} /conf/linkis-mg-gateway.properties
- database script execution, linkis itself needs to use the database, but when we execute the script of the inserted data of Linkis 1.3.0, we found an error. We directly deleted the data of the error part at that time.
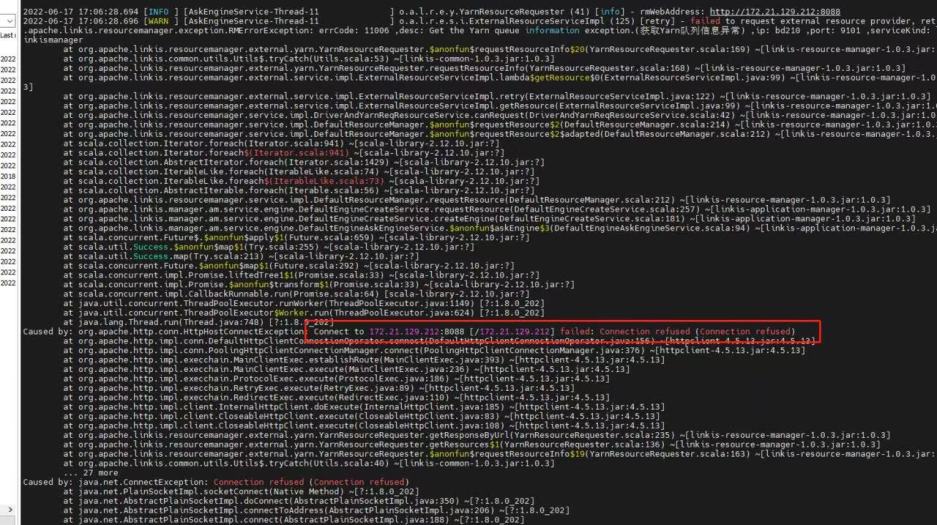
- Yarn's certification. When performing the spark task, the task will be submitted to the queue. The resource information of the queue will be obtained first to determine whether there is a resource to submit. For certification, if the file authentication is enabled, the file needs to be placed in the corresponding directory of the server, and the information is updated in the linkis_cg_rm_extRNAL_Resource_Provider library table.
Install web front end
- WEB side uses nginx as a static resource server, download the front -end installation package and decompress it, and place it on the directory corresponding to the Nginx server
scriptis tool installation
- Scriptis is a pure front -end project. As a component integrates in the web code component of DSS, we only need to compile the DSSWEB project for separate Scriptis modules, upload the compiled static resources to Visit, note: Linkis stand -by -machine deployment defaults to use session for verification. You need to log in to the Linkis management desk first, and then log in to Scriptis to use.
Nginx deployment for example
nginx.conf
upstream linkisServer{
server ip:port;
server ip:port;
}
Server {
Listen 8088;# Access port
Server_name localhost;
#Charset Koi8-R;
#access_log /var/log/nginx/host.access.log main;
#Scriptis static resources
local /scriptis {
# Modify to your own front path
alias/home/nginx/scriptis-weight; # static file directory
#Root/Home/Hadoop/DSS/Web/DSS/Linkis;
index index.html index.html;
}
#The default resource path points to the static resource of the front end of the management platform
location / {
# Modify to your own front path
root/Home/Nginx/Linkis-Web/DIST; # r r r r
#Root/Home/Hadoop/DSS/Web/DSS/Linkis;
index index.html index.html;
}
local /ws {
Proxy_pass http:// linkisserver/api #back -end linkis address
proxy_http_version 1.1;
proxy_set_header upgrade $ http_upgrade;
proxy_set_header connection upgrade;
}
location /api {
proxy_pass http:// linkisserver/api; #The address of the back end linkis
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header x_real_ipP $remote_addr;
proxy_set_header remote_addr $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_http_version 1.1;
proxy_connect_timeout 4s;
proxy_read_timeout 600s;
proxy_send_timeout 12s;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection upgrade;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
}
How to check the question
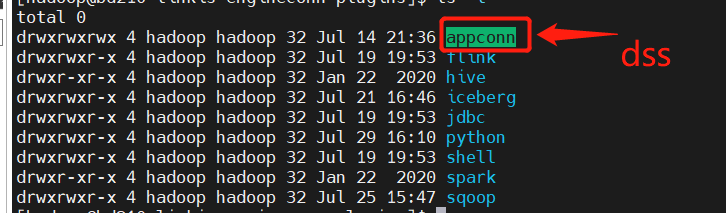
- There are more than 100 modules in Linkis, and the final service has 7 services, which are linkis-cg -ngineconnmanager, linkis-cg -ngineplugin, linkis-cg-entrance, linkis-cg-linkisManager, Linkis-Mg-Gateway, Linkis-Mg-Eureka, Linkis-PS-PublicService, each module has this different features. Among them, Linkis-CG-ENGINECONNMANAGER is responsible for managing the start-engine service, which will generate the corresponding engine script to pull up the engine. Services, so our team launched the Linkis-CG-ENGINECONNMANAGER alone on the server for sufficient resources to execute on the server.
- The execution of engines like JDBC, Spark.hedu and other engines require some JAR package support. When the linkis species is called material, these jar packs will be hit in the linkis-cg-oblmphin engine when packaging , Conf and LIB directory will appear. When starting this service, two packages will be uploaded to the configuration directory, which will generate two ZIP files. We use OSS to store these material information. Download it to the Linkis-CG-ENGINECONNMANAGER service, and then configure the following two configurations of wds.linkis.enginecoon.public.dir and wds.linkis.enginecoon.root.dir, then the bag will be pulled to WDS. Linkis.engineCoon.public.dir is the directory of wds.linkis.enginecoon.root.dir. .dir.
- If you want to check the engine log, you can see the directory under wds.linkis.enginecoon.root.dir configuration. Of course, the log information will be displayed on the log of the scriptis page. Just paste it to find it.

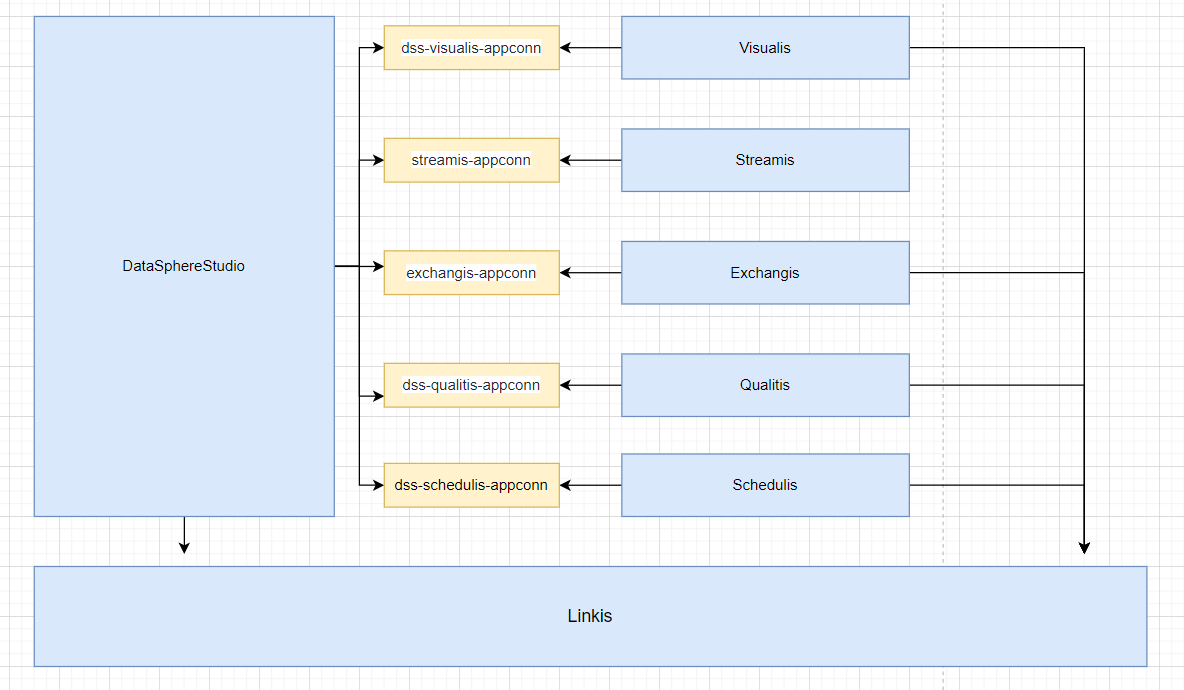
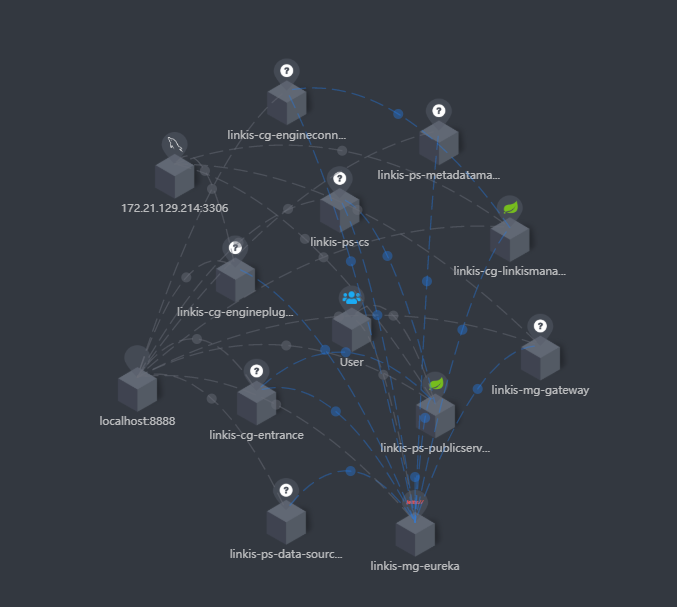 At the same time, you can also clearly see the call link in the trace, as shown in the following figure, which is also convenient for you to locate the error log file of the specific service
At the same time, you can also clearly see the call link in the trace, as shown in the following figure, which is also convenient for you to locate the error log file of the specific service

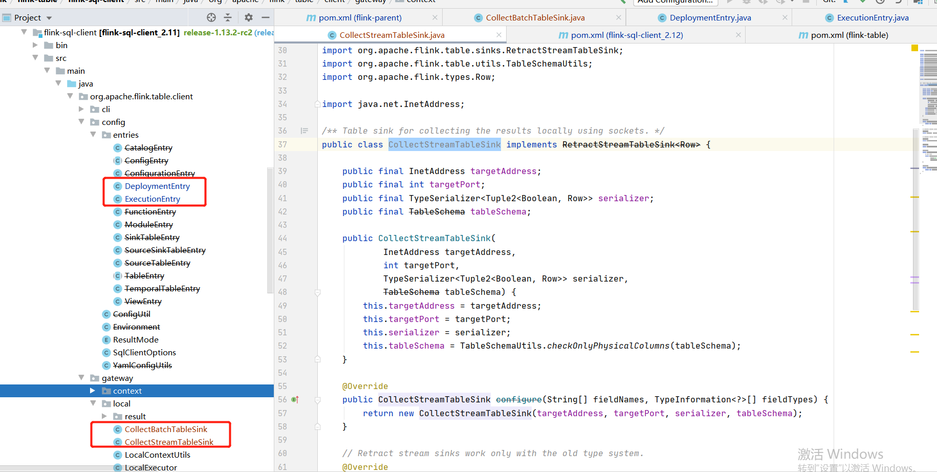
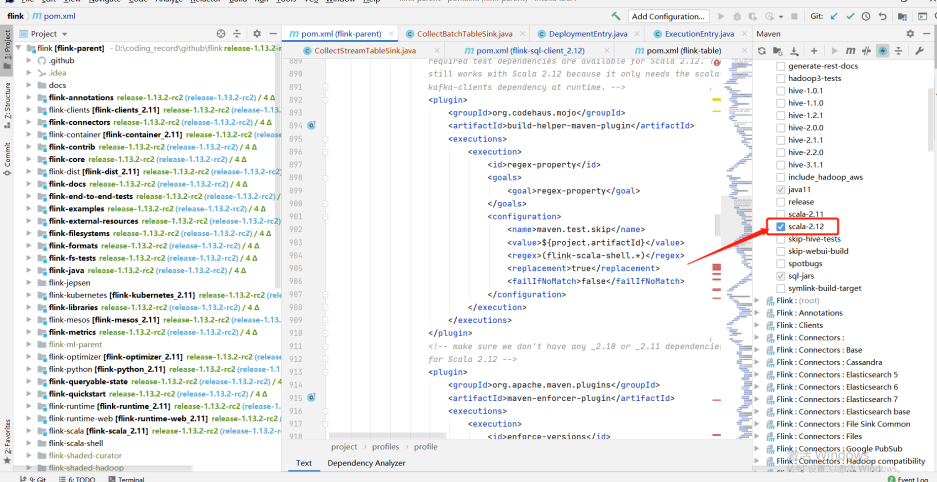
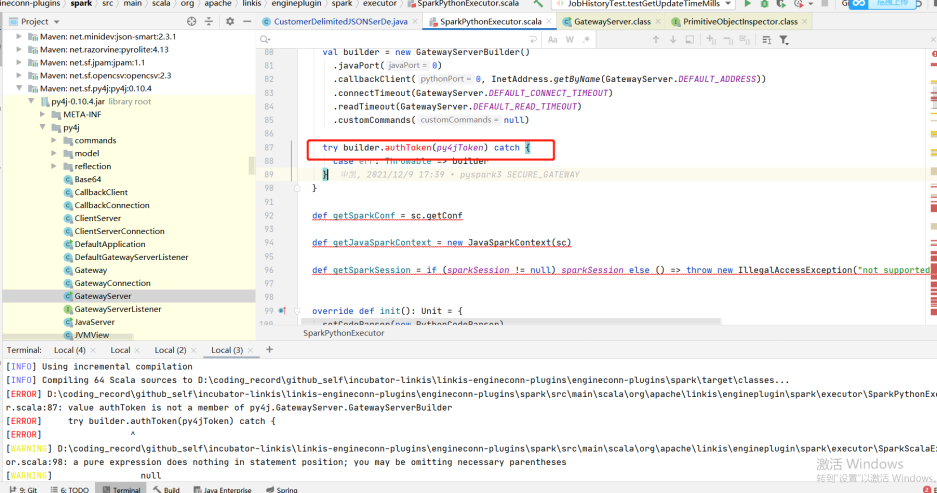


 For example, for qualitis, the following IP and host ports are determined according to their specific use
For example, for qualitis, the following IP and host ports are determined according to their specific use