Job submission, preparation and execution process
The submission and execution of computing tasks (Job) is the core capability provided by Linkis. It almost colludes with all modules in the Linkis computing governance architecture and occupies a core position in Linkis.
The whole process, starting at submitting user's computing tasks from the client and ending with returning final results, is divided into three stages: submission -> preparation -> executing. The details are shown in the following figure.
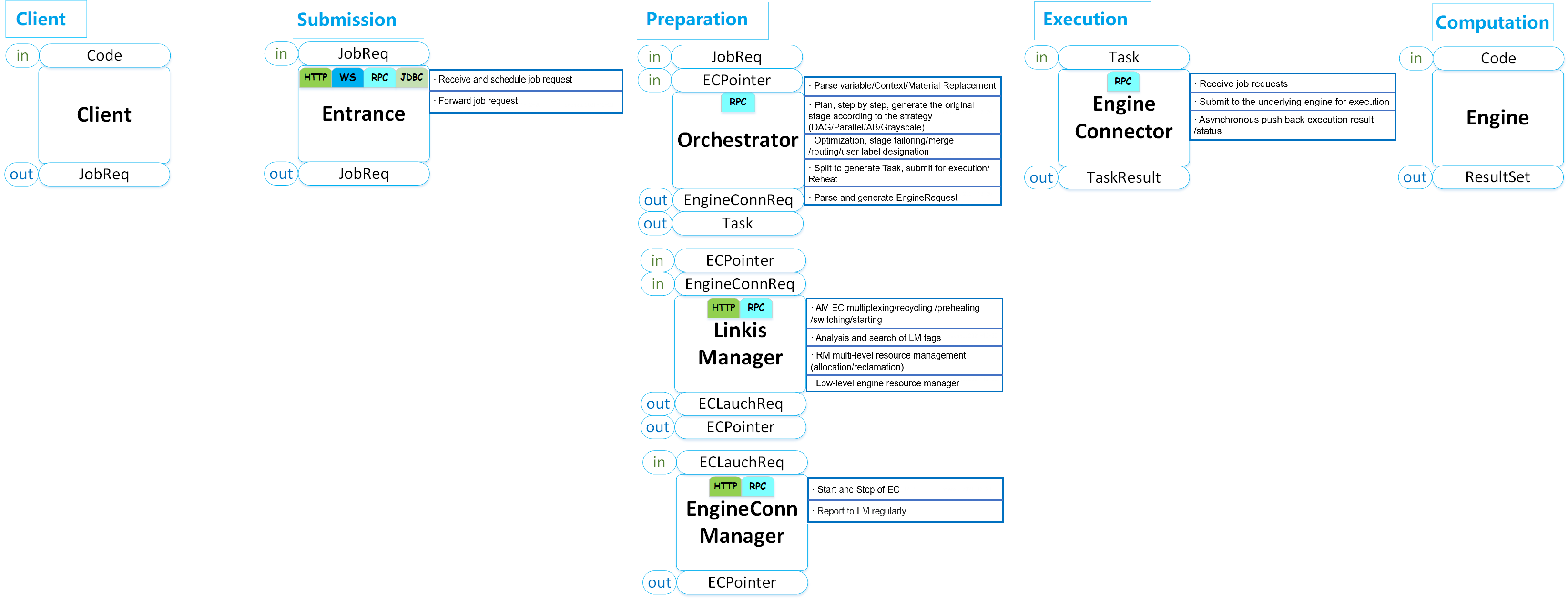
Among them:
Entrance, as the entrance to the submission stage, provides task reception, scheduling and job information forwarding capabilities. It is the unified entrance for all computing tasks. It will forward computing tasks to Orchestrator for scheduling and execution.
Orchestrator, as the entrance to the preparation phase, mainly provides job analysis, orchestration and execution capabilities.
Linkis Manager: The management center of computing governance capabilities. Its main responsibilities are as follows:
- ResourceManager:Not only has the resource management capabilities of Yarn and Linkis EngineConnManager, but also provides tag-based multi-level resource allocation and recovery capabilities, allowing ResourceManager to have full resource management capabilities across clusters and across computing resource types;
- AppManager: Coordinate and manage all EngineConnManager and EngineConn, including the life cycle of EngineConn application, reuse, creation, switching, and destruction to AppManager for management;
- LabelManager: Based on multi-level combined labels, it will provide label support for the routing and management capabilities of EngineConn and EngineConnManager across IDC and across clusters;
- EngineConnPluginServer: Externally provides the resource generation capabilities required to start an EngineConn and EngineConn startup command generation capabilities.
EngineConnManager: It is the manager of EngineConn, which provides engine life-cycle management, and at the same time reports load information and its own health status to RM.
EngineConn: It is the actual connector between Linkis and the underlying computing storage engines. All user computing and storage tasks will eventually be submitted to the underlying computing storage engine by EngineConn. According to different user scenarios, EngineConn provides full-stack computing capability framework support for interactive computing, streaming computing, off-line computing, and data storage tasks.
1. Submission Stage
The submission phase is mainly the interaction of Client -> Linkis Gateway -> Entrance, and the process is as follows:

- First, the Client (such as the front end or the client) initiates a Job request, and the job request information is simplified as follows (for the specific usage of Linkis, please refer to How to use Linkis):
POST /api/rest_j/v1/entrance/submit
{
"executionContent": {"code": "show tables", "runType": "sql"},
"params": {"variable": {}, "configuration": {}}, //not required
"source": {"scriptPath": "file:///1.hql"}, //not required, only used to record code source
"labels": {
"engineType": "spark-2.4.3", //Specify engine
"userCreator": "username-IDE" // Specify the submission user and submission system
}
}
- After Linkis-Gateway receives the request, according to the serviceName in the URI
/api/rest_j/v1/${serviceName}/.+, it will confirm the microservice name for routing and forwarding. Here Linkis-Gateway will parse out the name as entrance and Job is forwarded to the Entrance microservice. It should be noted that if the user specifies a routing label, the Entrance microservice instance with the corresponding label will be selected for forwarding according to the routing label instead of random forwarding. - After Entrance receives the Job request, it will first simply verify the legitimacy of the request, then use RPC to call JobHistory to persist the job information, and then encapsulate the Job request as a computing task, put it in the scheduling queue, and wait for it to be consumed by consumption thread.
- The scheduling queue will open up a consumption queue and a consumption thread for each group. The consumption queue is used to store the user computing tasks that have been preliminarily encapsulated. The consumption thread will continue to take computing tasks from the consumption queue for consumption in a FIFO manner. The current default grouping method is Creator + User (that is, submission system + user). Therefore, even if it is the same user, as long as it is a computing task submitted by different systems, the actual consumption queues and consumption threads are completely different, and they are completely isolated from each other. (Reminder: Users can modify the grouping algorithm as needed)
- After the consuming thread takes out the calculation task, it will submit the calculation task to Orchestrator, which officially enters the preparation phase.
2. Preparation Stage
There are two main processes in the preparation phase. One is to apply for an available EngineConn from LinkisManager to submit and execute the following computing tasks. The other is Orchestrator to orchestrate the computing tasks submitted by Entrance, and to convert a user's computing request into a physical execution tree and handed over to the execution phase where a computing task actually being executed.
2.1 Apply to LinkisManager for available EngineConn
If the user has a reusable EngineConn in LinkisManager, the EngineConn is directly locked and returned to Orchestrator, and the entire application process ends.
How to define a reusable EngineConn? It refers to those that can match all the label requirements of the computing task, and the EngineConn's own health status is Healthy (the load is low and the actual status is Idle). Then, all the EngineConn that meets the conditions are sorted and selected according to the rules, and finally the best one is locked.
If the user does not have a reusable EngineConn, a process to request a new EngineConn will be triggered at this time. Regarding the process, please refer to: How to add an EngineConn.
2.2 Orchestrate a computing task
Orchestrator is mainly responsible for arranging a computing task (JobReq) into a physical execution tree (PhysicalTree) that can be actually executed, and providing the execution capabilities of the Physical tree.
Here we first focus on Orchestrator's computing task scheduling capabilities. A flow chart is shown below:
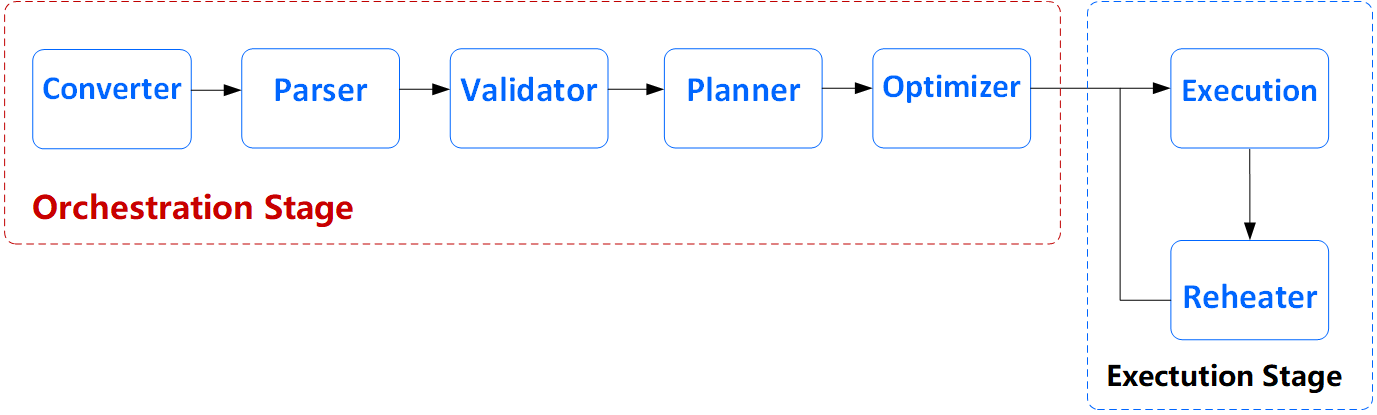
The main process is as follows:
- Converter: Complete the conversion of the JobReq (task request) submitted by the user to Orchestrator's ASTJob. This step will perform parameter check and information supplementation on the calculation task submitted by the user, such as variable replacement, etc.
- Parser: Complete the analysis of ASTJob. Split ASTJob into an AST tree composed of ASTJob and ASTStage.
- Validator: Complete the inspection and information supplement of ASTJob and ASTStage, such as code inspection, necessary Label information supplement, etc.
- Planner: Convert an AST tree into a Logical tree. The Logical tree at this time has been composed of LogicalTask, which contains all the execution logic of the entire computing task.
- Optimizer: Convert a Logical tree to a Physical tree and optimize the Physical tree.
In a physical tree, the majority of nodes are computing strategy logic. Only the middle ExecTask truly encapsulates the execution logic which will be further submitted to and executed at EngineConn. As shown below:
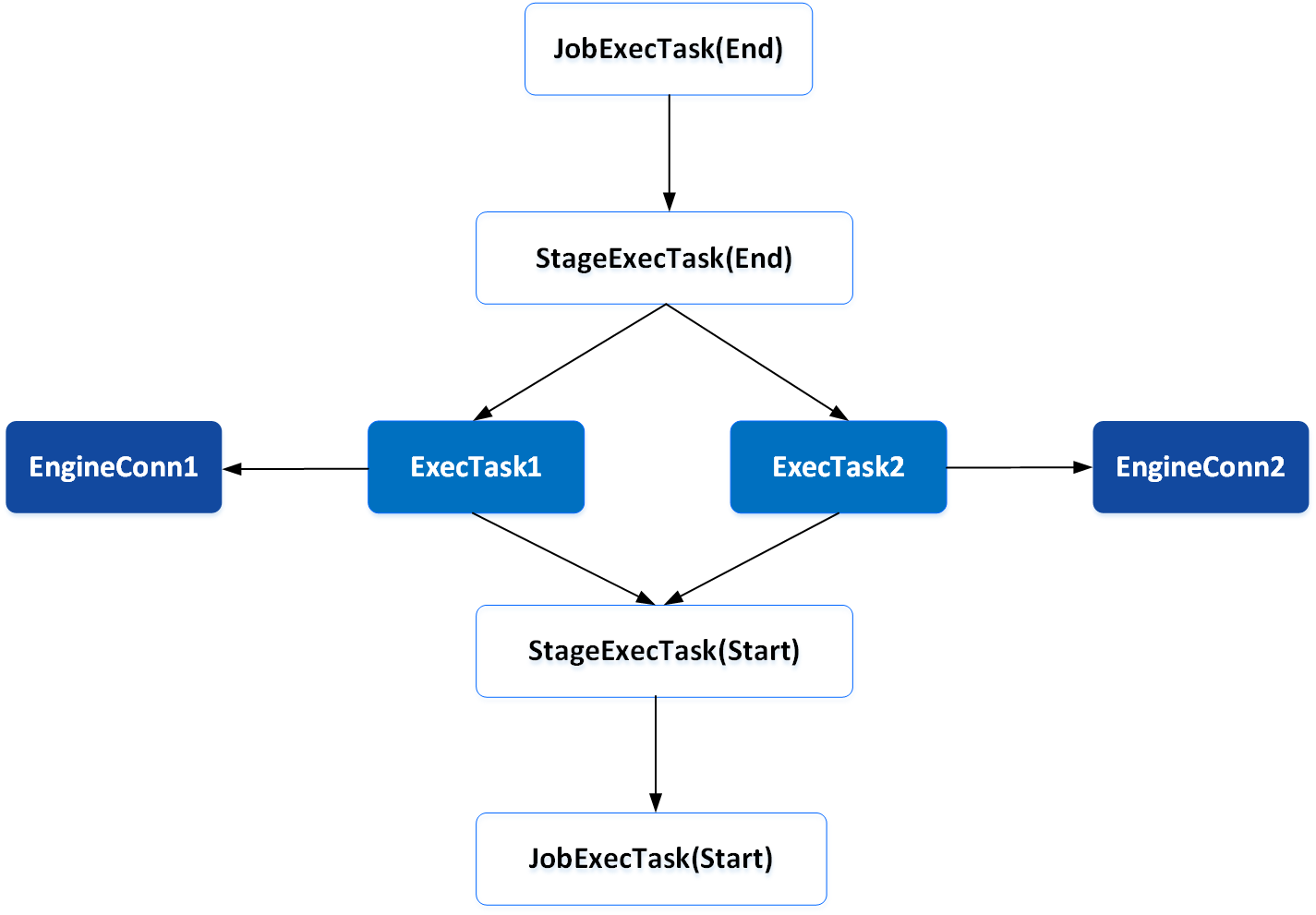
Different computing strategies have different execution logics encapsulated by JobExecTask and StageExecTask in the Physical tree.
The execution logic encapsulated by JobExecTask and StageExecTask in the Physical tree depends on the specific type of computing strategy.
For example, under the multi-active computing strategy, for a computing task submitted by a user, the execution logic submitted to EngineConn of different clusters for execution is encapsulated in two ExecTasks, and the related strategy logic is reflected in the parent node (StageExecTask(End)) of the two ExecTasks.
Here, we take the multi-reading scenario under the multi-active computing strategy as an example.
In multi-reading scenario, only one result of ExecTask is required to return. Once the result is returned , the Physical tree can be marked as successful. However, the Physical tree only has the ability to execute sequentially according to dependencies, and cannot terminate the execution of each node. Once a node is canceled or fails to execute, the entire Physical tree will be marked as failure. At this time, StageExecTask (End) is needed to ensure that the Physical tree can not only cancel the ExecTask that failed to execute, but also continue to upload the result set generated by the Successful ExecTask, and let the Physical tree continue to execute. This is the execution logic of computing strategy represented by StageExecTask.
The orchestration process of Linkis Orchestrator is similar to many SQL parsing engines (such as Spark, Hive's SQL parser). But in fact, the orchestration capability of Linkis Orchestrator is realized based on the computing governance field for the different computing governance needs of users. The SQL parsing engine is a parsing orchestration oriented to the SQL language. Here is a simple distinction:
- What Linkis Orchestrator mainly wants to solve is the orchestration requirements caused by different computing tasks for computing strategies. For example, in order to be multi-active, Orchestrator will submit a calculation task for the user, based on the "multi-active" computing strategy requirements, compile a physical tree, so as to submit to multiple clusters to perform this calculation task. And in the process of constructing the entire Physical tree, various possible abnormal scenarios have been fully considered, and they have all been reflected in the Physical tree.
- The orchestration ability of Linkis Orchestrator has nothing to do with the programming language. In theory, as long as an engine has adapted to Linkis, all the programming languages it supports can be orchestrated, while the SQL parsing engine only cares about the analysis and execution of SQL, and is only responsible for parsing a piece of SQL into one executable Physical tree, and finally calculate the result.
- Linkis Orchestrator also has the ability to parse SQL, but SQL parsing is just one of Orchestrator Parser's analytic implementations for the SQL programming language. The Parser of Linkis Orchestrator also considers introducing Apache Calcite to parse SQL. It supports splitting a user SQL that spans multiple computing engines (must be a computing engine that Linkis has docked) into multiple sub SQLs and submitting them to each corresponding engine during the execution phase. Finally, a suitable calculation engine is selected for summary calculation.
After the analysis and arrangement of Linkis Orchestrator, the computing task has been transformed into a executable physical tree. Orchestrator will submit the Physical tree to Orchestrator's Execution module and enter the final execution stage.
3. Execution Stage
The execution stage is mainly divided into the following two steps, these two steps are the last two phases of capabilities provided by Linkis Orchestrator:
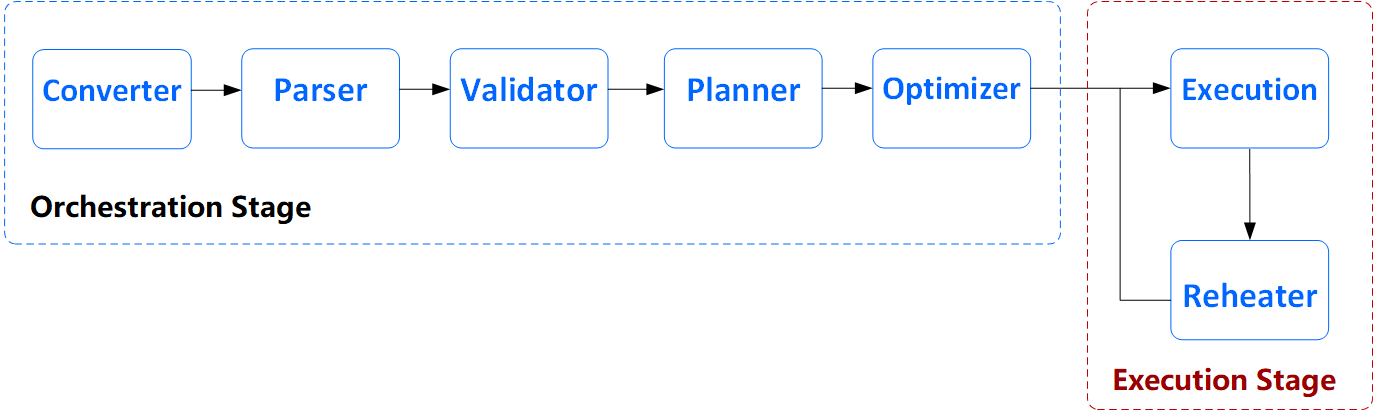
The main process is as follows:
- Execution: Analyze the dependencies of the Physical tree, and execute them sequentially from the leaf nodes according to the dependencies.
- Reheater: Once the execution of a node in the Physical tree is completed, it will trigger a reheat. Reheating allows the physical tree to be dynamically adjusted according to the real-time execution.For example: it is detected that a leaf node fails to execute, and it supports retry (if it is caused by throwing ReTryExecption), the Physical tree will be automatically adjusted, and a retry parent node with exactly the same content is added to the leaf node .
Let us go back to the Execution stage, where we focus on the execution logic of the ExecTask node that encapsulates the user computing task submitted to EngineConn.
- As mentioned earlier, the first step in the preparation phase is to obtain a usable EngineConn from LinkisManager. After ExecTask gets this EngineConn, it will submit the user's computing task to EngineConn through an RPC request.
- After EngineConn receives the computing task, it will asynchronously submit it to the underlying computing storage engine through the thread pool, and then immediately return an execution ID.
- After ExecTask gets this execution ID, it can then use the ID to asynchronously pull the execution status of the computing task (such as: status, progress, log, result set, etc.).
- At the same time, EngineConn will monitor the execution of the underlying computing storage engine in real time through multiple registered Listeners. If the computing storage engine does not support registering Listeners, EngineConn will start a daemon thread for the computing task and periodically pull the execution status from the computing storage engine.
- EngineConn will pull the execution status back to the microservice where Orchestrator is located in real time through RCP request.
- After the Receiver of the microservice receives the execution status, it will broadcast it through the ListenerBus, and the Orchestrator Execution will consume the event and dynamically update the execution status of the Physical tree.
- The result set generated by the calculation task will be written to storage media such as HDFS at the EngineConn side. EngineConn returns only the result set path through RPC, Execution consumes the event, and broadcasts the obtained result set path through ListenerBus, so that the Listener registered by Entrance with Orchestrator can consume the result set path and write the result set path Persist to JobHistory.
- After the execution of the computing task on the EngineConn side is completed, through the same logic, the Execution will be triggered to update the state of the ExecTask node of the Physical tree, so that the Physical tree will continue to execute until the entire tree is completely executed. At this time, Execution will broadcast the completion status of the calculation task through ListenerBus.
- After the Entrance registered Listener with the Orchestrator consumes the state event, it updates the job state to JobHistory, and the entire task execution is completed.
Finally, let's take a look at how the client side knows the state of the calculation task and obtains the calculation result in time, as shown in the following figure:
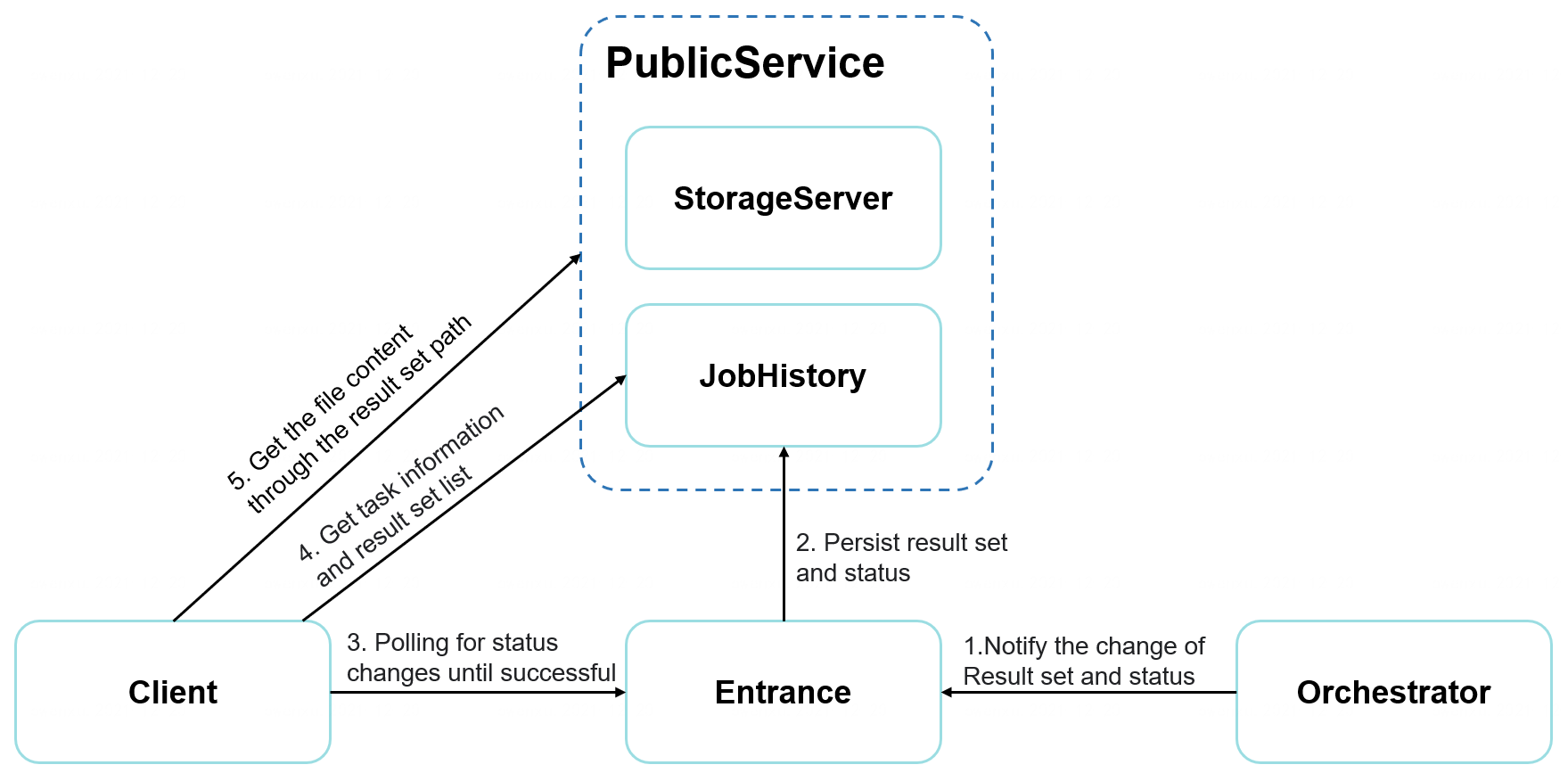
The specific process is as follows:
- The client periodically polls to request Entrance to obtain the status of the computing task.
- Once the status is flipped to success, it sends a request for job information to JobHistory, and gets all the result set paths.
- Initiate a query file content request to PublicService through the result set path, and obtain the content of the result set.
Since then, the entire process of job submission -> preparation -> execution have been completed.