Job Submission
Linkis task execution is the core function of Linkis. It calls to Linkis's computing governance service, public enhancement service, and three-tier services of microservice governance. Now it supports the execution of tasks of OLAP, OLTP, Streaming and other engine types. This article will discuss OLAP The process of task submission, preparation, execution, and result return of the type engine is introduced.
Keywords:
LinkisMaster: The management service in the computing governance service layer of Linkis mainly includes several management and control services such as AppManager, ResourceManager, and LabelManager. Formerly known as LinkisManager service Entrance: The entry service in the computing governance service layer, which completes the functions of task scheduling, status control, task information push, etc. Orchestrator: Linkis' orchestration service provides powerful orchestration and computing strategy capabilities to meet the needs of multiple application scenarios such as multi-active, active-standby, transaction, replay, current limiting, heterogeneous and mixed computing. At this stage, Orchestrator is relied on by the Entrance service EngineConn (EC): Engine connector, responsible for accepting tasks and submitting them to underlying engines such as Spark, hive, Flink, Presto, trino, etc. for execution EngineConnManager (ECM): Linkis' EC process management service, responsible for controlling the life cycle of EngineConn (start, stop) LinkisEnginePluginServer: This service is responsible for managing the startup materials and configuration of each engine, and also provides the startup command acquisition of each EngineConn, as well as the resources required by each EngineConn PublicEnhencementService (PES): A public enhancement service, a module that provides functions such as unified configuration management, context service, material library, data source management, microservice management, and historical task query for other microservice modules
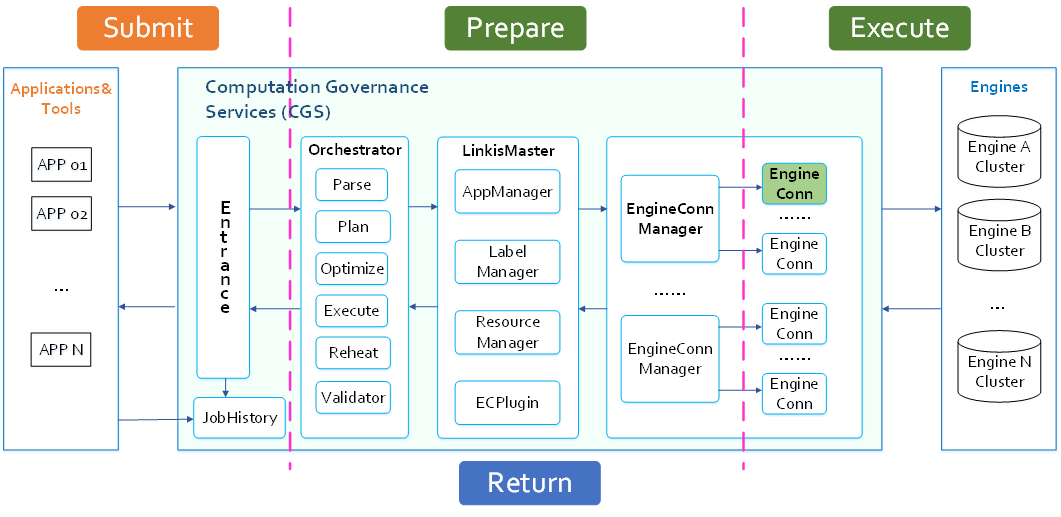
1. Linkis interactive task execution architecture
1.1, Task execution thinking
Before the existing Linkis 1.0 task execution architecture, it has undergone many evolutions. From the very beginning, various FullGC caused the service to crash when there were many users, to how the scripts developed by users support multi-platform , multi-tenancy, strong control, high concurrent operation, we encountered the following problems:
- How to support tens of thousands of concurrent tenants and isolate each other?
- How to support context unification, user-defined UDFs, custom variables, etc. to support the use of multiple systems?
- How to support high availability so that the tasks submitted by users can run normally?
- How to support the underlying engine log, progress, and status of the task to be pushed to the front end in real time?
- How to support multiple types of tasks to submit sql, python, shell, scala, java, etc.
1.2, Linkis task execution design
Based on the above five questions, Linkis divides the OLTP task into four stages, which are:
- Submission stage: The APP is submitted to the CG-Entrance service of Linkis to the completion of the persistence of the task (PS-JobHistory) and various interceptor processing of the task (dangerous syntax, variable substitution, parameter checking) and other steps, and become a producer Consumer concurrency control;
- Preparation stage: The task is scheduled by the Scheduler in Entrance to the Orchestrator module for task arrangement, and completes the EngineConn application to the LinkisMaster. During this process, the tenant's resources will be managed and controlled;
- Execution stage: The task is submitted from Orchestrator to EngineConn for execution, and EngineConn specifically submits the underlying engine for execution, and pushes the task information to the caller in real time;
- Result return stage: return results to the caller, support json and io streams to return result sets
The overall task execution architecture of Linkis is shown in the following figure:
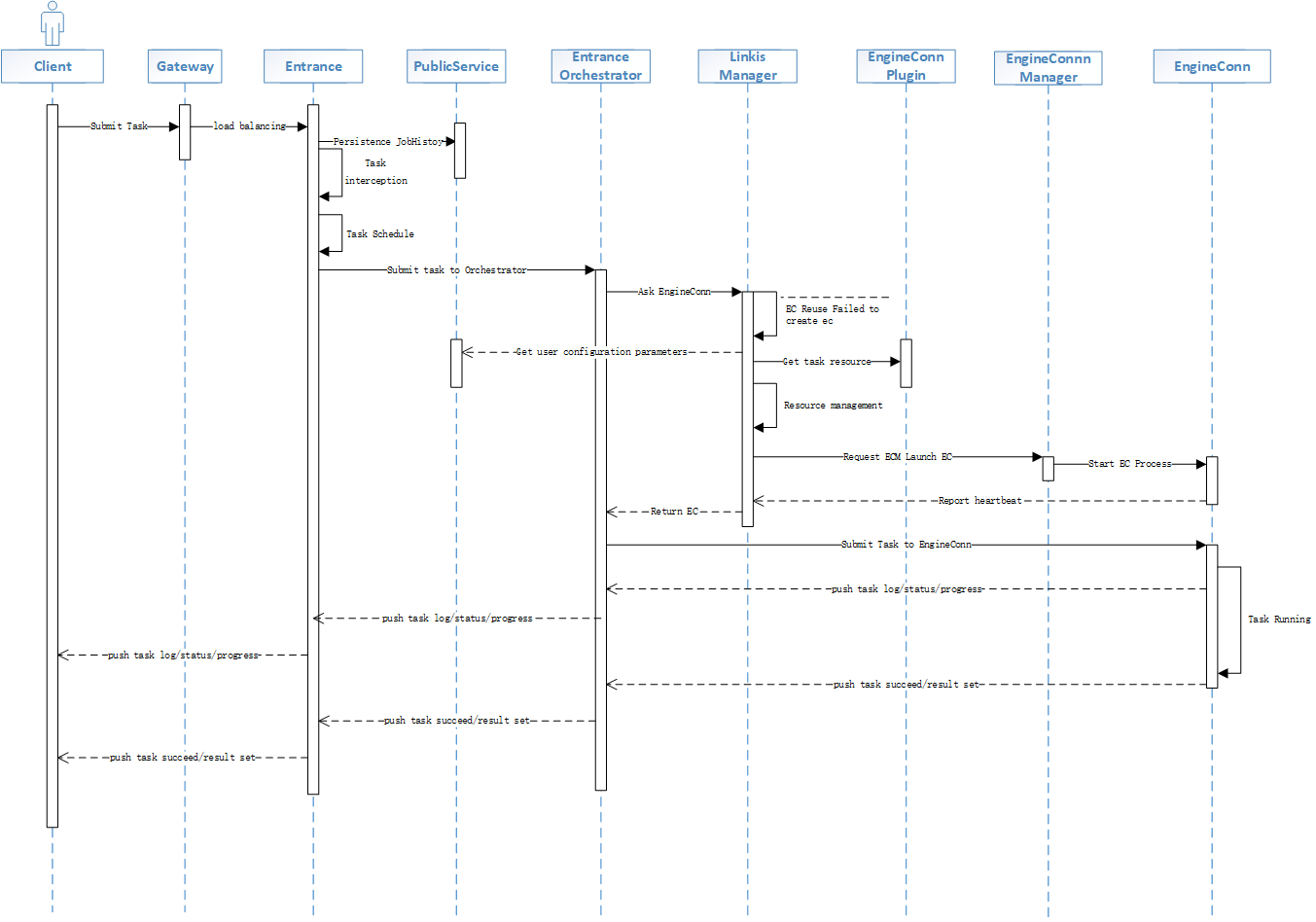
2. Introduction to the task execution process
First of all, let's give a brief introduction to the processing flow of OLAP tasks. An overall execution flow of the task is shown in the following figure:
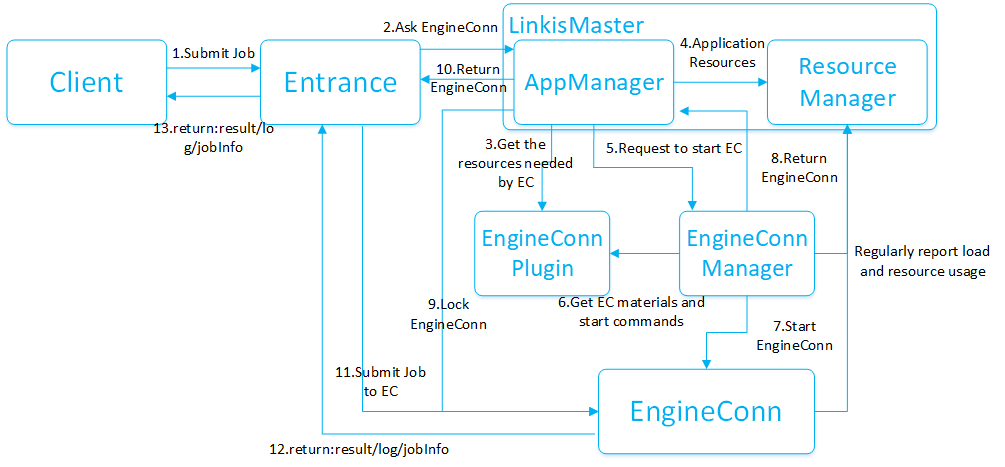
The whole task involves all the services of all computing governance. After the task is forwarded to Linkis's population service Entrance through the Gateway, it will perform multi-level scheduling (producer-consumer mode) through the label of the task. The FIFO mode completes task scheduling and execution. Entrance then submits the task to Orchestrator for task scheduling and submission. Orchestrator will complete the EC application to LinkisMaster. During this process, resource management and engine version selection will be performed through the task Label. EC. Orchestrator then submits the orchestrated task to the EC for execution. The EC will push the job log, progress, resource usage and other information to the Entrance service and push it to the caller. Next, we will give a brief introduction to the execution process of the task based on the above figure and the four stages of the task (submit, prepare, execute, and return).
2.1 Job submission stage
Job submission phase Linkis supports multiple types of tasks: SQL, Python, Shell, Scala, Java, etc., supports different submission interfaces, and supports Restful/JDBC/Python/Shell and other submission interfaces. Submitting tasks mainly includes task code, labels, parameters and other information. The following is an example of RestFul: Initiate a Spark Sql task through the Restfu interface
"method": "/api/rest_j/v1/entrance/submit",
"data": {
"executionContent": {
"code": "select * from table01",
"runType": "sql"
},
"params": {
"variable": {// task variable
"testvar": "hello"
},
"configuration": {
"runtime": {// task runtime params
"jdbc.url": "XX"
},
"startup": { // ec start up params
"spark.executor.cores": "4"
}
}
},
"source": { //task source information
"scriptPath": "file:///tmp/hadoop/test.sql"
},
"labels": {
"engineType": "spark-2.4.3",
"userCreator": "hadoop-IDE"
}
}
- The task will first be submitted to Linkis's gateway linkis-mg-gateway service. Gateway will forward it to the corresponding Entrance service according to whether the task has a routeLabel. If there is no RouteLabel, it will be forwarded to an Entrance service randomly.
- After Entrance receives the corresponding job, it will call the RPC of the JobHistory module in the PES to persist the job information, and parse the parameters and code to replace the custom variables, and submit them to the scheduler (default FIFO scheduling) ) The scheduler will group tasks by tags, and tasks with different tags do not affect scheduling.
- After Entrance is consumed by the FIFO scheduler, it will be submitted to the Orchestrator for orchestration and execution, and the submission phase of the task is completed. A brief description of the main classes involved:
EntranceRestfulApi: Controller class of entry service, operations such as task submission, status, log, result, job information, task kill, etc.
EntranceServer: task submission entry, complete task persistence, task interception analysis (EntranceInterceptors), and submit to the scheduler
EntranceContext: Entrance's context holding class, including methods for obtaining scheduler, task parsing interceptor, logManager, persistence, listenBus, etc.
FIFOScheduler: FIFO scheduler for scheduling tasks
EntranceExecutor: The scheduled executor, after the task is scheduled, it will be submitted to the EntranceExecutor for execution
EntranceJob: The job task scheduled by the scheduler, and the JobRequest submitted by the user is parsed through the EntranceParser to generate a one-to-one correspondence with the JobRequest
The task status is now queued
2.2 Job preparation stage
Entrance's scheduler will generate different consumers to consume tasks according to the Label in the Job. When the task is consumed and modified to Running, it will enter the preparation state, and the task will be prepared after the corresponding task. Phase begins. It mainly involves the following services: Entrance, LinkisMaster, EnginepluginServer, EngineConnManager, and EngineConn. The following services will be introduced separately.
2.2.1 Entrance steps:
- The consumer (FIFOUserConsumer) consumes the supported concurrent number configured by the corresponding tag, and schedules the task consumption to the Orchestrator for execution
- First, Orchestrator arranges the submitted tasks. For ordinary hive and Spark single-engine tasks, it is mainly task parsing, label checking and verification. For multi-data source mixed computing scenarios, different tasks will be split and submitted to Different data sources for execution, etc.
- In the preparation phase, another important thing for the Orchestrator is to request the LinkisMaster to obtain the EngineConn for executing the task. If LinkisMaster has a corresponding EngineConn that can be reused, it will return directly, if not, create an EngineConn.
- Orchestrator gets the task and submits it to EngineConn for execution. The preparation phase ends and the job execution phase is entered. A brief description of the main classes involved:
## Entrance
FIFOUserConsumer: The consumer of the scheduler, which will generate different consumers according to the tags, such as IDE-hadoop and spark-2.4.3. Consume submitted tasks. And control the number of tasks running at the same time, configure the number of concurrency through the corresponding tag: wds.linkis.rm.instance
DefaultEntranceExecutor: The entry point for task execution, which initiates a call to the orchestrator: callExecute
JobReq: The task object accepted by the scheduler, converted from EntranceJob, mainly including code, label information, parameters, etc.
OrchestratorSession: Similar to SparkSession, it is the entry point of the orchestrator. Normal singleton.
Orchestration: The return object of the JobReq orchestrated by the OrchestratorSession, which supports execution and printing of execution plans, etc.
OrchestrationFuture: Orchestration selects the return of asynchronous execution, including common methods such as cancel, waitForCompleted, and getResponse
Operation: An interface used to extend operation tasks. Now LogOperation for obtaining logs and ProgressOperation for obtaining progress have been implemented.
## Orchestrator
CodeLogicalUnitExecTask: The execution entry of code type tasks. After the task is finally scheduled and run, the execute method of this class will be called. First, it will request EngineConn from LinkisMaster and then submit for execution.
DefaultCodeExecTaskExecutorManager: EngineConn responsible for managing code types, including requesting and releasing EngineConn
ComputationEngineConnManager: Responsible for LinkisMaster to connect, request and release ENgineConn
2.2.2 LinkisMaster steps:
- LinkisMaster receives the request EngineConn request from the Entrance service for processing
- Determine if there is an EngineConn that can be reused by the corresponding Label, and return directly if there is
- If not, enter the process of creating EngineConn:
- First select the appropriate EngineConnManager service through Label.
- Then get the resource type and resource usage of this request EngineConn by calling EnginePluginServer,
- According to the resource type and resource, determine whether the corresponding Label still has resources, if so, enter the creation, otherwise throw a retry exception
- Request the EngineConnManager of the first step to start EngineConn
- Wait for the EngineConn to be idle, return the created EngineConn, otherwise judge whether the exception can be retried
- Lock the created EngineConn and return it to Entrance. Note that it will receive the corresponding request ID after sending the EC request for the asynchronous request Entrance. After the LinkisMaster request is completed, it will actively pass the corresponding Entrance service.
A brief description of the main classes involved:
## LinkisMaster
EngineAskEngineService: LinkisMaster is responsible for processing the engine request processing class. The main logic judges whether there is an EngineConn that can be reused by calling EngineReuseService, otherwise calling EngineCreateService to create an EngineConn
EngineCreateService: Responsible for creating EngineConn, the main steps are:
##LinkisEnginePluginServer
EngineConnLaunchService: Provides ECM to obtain the startup information of the corresponding engine type EngineConn
EngineConnResourceFactoryService: Provided to LinkisMaster to obtain the resources needed to start EngineConn corresponding to this task
EngineConnResourceService: Responsible for managing engine materials, including refreshing and refreshing all
## EngineConnManager
AbstractEngineConnLaunchService: Responsible for starting the request to start the EngineConn by accepting the LinkisMaster request, and completing the start of the EngineConn engine
ECMHook: It is used to process the pre and post operations before and after EngineConn is started. For example, hive UDF Jar is added to the classPath started by EngineConn.
It should be noted here that if the user has an available idle engine, the four steps 1, 2, 3, and 4 will be skipped;
2.3 Job execution phase
When the orchestrator in the Entrance service gets the EngineConn, it enters the execution phase. CodeLogicalUnitExecTask will submit the task to the EngineConn for execution, and the EngineConn will create different executors through the corresponding CodeLanguageLabel for execution. The main steps are as follows:
- CodeLogicalUnitExecTask submits tasks to EngineConn via RPC
- EngineConn determines whether there is a corresponding CodeLanguageLabel executor, if not, create it
- Submit to Executor for execution, and execute by linking to the specific underlying engine execution, such as Spark submitting sql, pyspark, and scala tasks through sparkSession
- The task status flow is pushed to the Entrance service in real time
- By implementing log4jAppender, SendAppender pushes logs to Entrance service via RPC
- Push task progress and resource information to Entrance in real time through timed tasks
A brief description of the main classes involved:
ComputationTaskExecutionReceiver: The service class used by the Entrance server orchestrator to receive all RPC requests from EngineConn, responsible for receiving progress, logs, status, and result sets pushed to the last caller through the ListenerBus mode
TaskExecutionServiceImpl: The service class for EngineConn to receive all RPC requests from Entrance, including task execution, status query, task Kill, etc.
ComputationExecutor: specific task execution parent class, such as Spark is divided into SQL/Python/Scala Executor
ComputationExecutorHook: Hook before and after Executor creation, such as initializing UDF, executing default UseDB, etc.
EngineConnSyncListener: ResultSetListener/TaskProgressListener/TaskStatusListener is used to monitor the progress, result set, and progress of the Executor during the execution of the task.
SendAppender: Responsible for pushing logs from EngineConn to Entrance
2.4 Job result push stage
This stage is relatively simple and is mainly used to return the result set generated by the task in EngineConn to the Client. The main steps are as follows:
- First, when EngineConn executes the task, the result set will be written, and the corresponding path will be obtained by writing to the file system. Of course, memory cache is also supported, and files are written by default.
- EngineConn returns the corresponding result set path and the number of result sets to Entrance
- Entrance calls JobHistory to update the result set path information to the task table
- Client obtains the result set path through task information and reads the result set A brief description of the main classes involved:
EngineExecutionContext: responsible for creating the result set and pushing the result set to the Entrance service
ResultSetWriter: Responsible for writing result sets to filesystems that support linkis-storage support, and now supports both local and HDFS. Supported result set types, table, text, HTML, image, etc.
JobHistory: Stores all the information of the task, including status, result path, indicator information, etc. corresponding to the entity class in the DB
ResultSetReader: The key class for reading the result set
3. Summary
Above we mainly introduced the entire execution process of the OLAP task of the Linkis Computing Governance Service Group CGS. According to the processing process of the task request, the task is divided into four parts: submit, prepare, execute, and return the result stage. CGS is mainly designed and implemented according to these 4 stages, serves these 4 stages, and provides powerful and flexible capabilities for each stage. In the submission stage, it mainly provides a common interface, receives tasks submitted by upper-layer application tools, and provides basic parsing and interception capabilities; in the preparation stage, it mainly completes the parsing and scheduling of tasks through the orchestrator Orchestrator and LinkisMaster, and does Resource control, and the creation of EngineConn; in the execution stage, the connection with the underlying engine is actually completed through the engine connector EngineConn. Usually, each user needs to start a corresponding underlying engine connector EC to connect to a different underlying engine. . The computing task is submitted to the underlying engine for actual execution through EC, and information such as status, log, and result is obtained, and; in the result return stage, the result information of the task execution is returned, and various return modes are supported, such as: file Streams, JSON, JDBC, etc. The overall timing diagram is as follows: