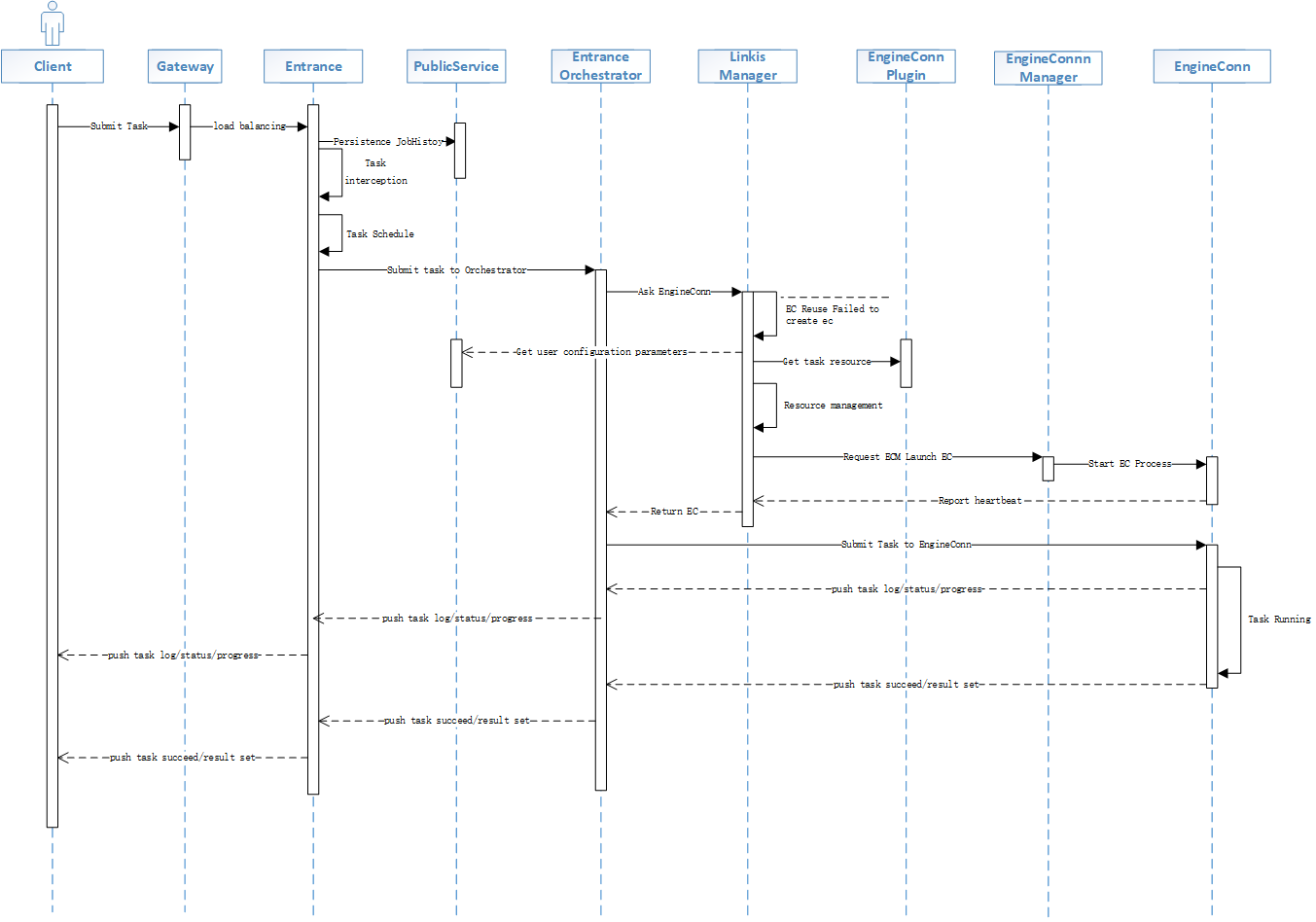
Linkis任务执行流程
Linkis任务执行是Linkis的核心功能,调用到Linkis的计算治理服务、公共增强服务,微服务治理的三层服务,现在已经支持了OLAP、OLTP、Streaming等引擎类型的任务执行,本文将对OLAP类型引擎的任务提交、准备、执行、结果返回等流程进行介绍。
关键名词:
LinkisMaster:Linkis的计算治理服务层架中的管理服务,主要包含了AppManager、ResourceManager、LabelManager等几个管控服务。原名LinkisManager服务 Entrance:计算治理服务层架中的入口服务,完成任务的调度、状态管控、任务信息推送等功能 Orchestrator:Linkis的编排服务,提供强大的编排和计算策略能力,满足多活、主备、事务、重放、限流、异构和混算等多种应用场景的需求。现阶段Orchestrator被Entrance服务所依赖 EngineConn(EC):引擎连接器,负责接受任务并提交给底层引擎如Spark、hive、Flink、Presto、trino等进行执行 EngineConnManager(ECM):Linkis 的EC进程管理服务,负责管控EngineConn的生命周期(启动、停止) LinkisEnginePluginServer:该服务负责管理各个引擎的启动物料和配置,另外提供每个EngineConn的启动命令获取,以及每个EngineConn所需要的资源 PublicEnhencementService(PES): 公共增强服务,为其他微服务模块提供统一配置管理、上下文服务、物料库、数据源管理、微服务管理和历史任务查询等功能的模块
一、Linkis交互式任务执行架构
1.1、任务执行思考
在现有Linkis1.0任务执行架构之前,也经历了多次演变,从最开始用户一多起来就各种FullGC导致服务崩溃,到用户开发的脚本如何支持多平台、多租户、强管控、高并发运行,我们遇见了如下几个问题:
- 如何支持租户户的上万并发并互相隔离?
- 如何支持上下文统一 ,用户定义的UDF、自定义变量等支持多个系统使用?
- 如何支持高可用,做到用户提交的任务能够正常运行完?
- 如何支持任务的底层引擎日志、进度、状态能够实时推送给前端?
- 如何支持多种类型的任务提交sql、python、shell、scala、java等
1.2、Linkis任务执行设计
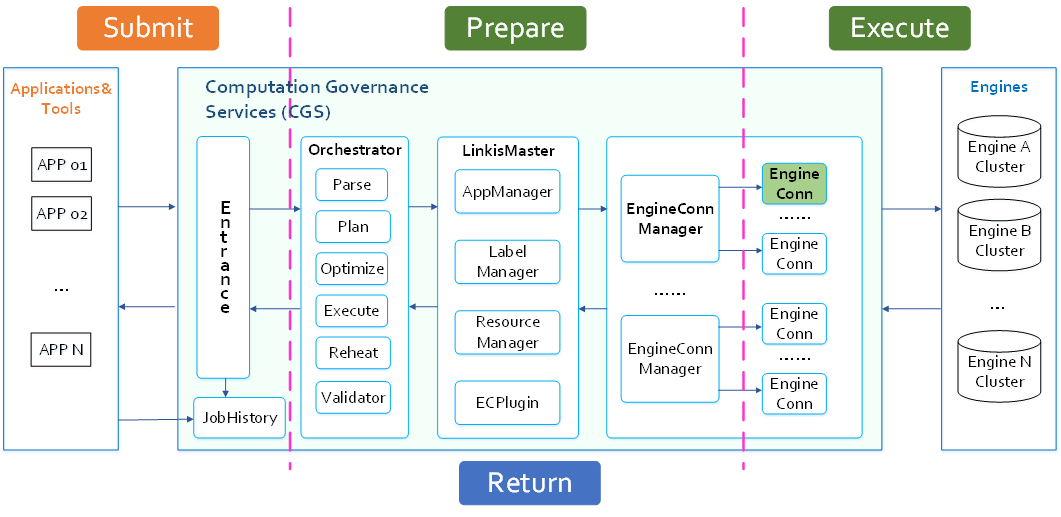
基于以上5个问题出发,Linkis将OLTP任务分成了四个阶段,分别是:
- 提交阶段:APP提交到Linkis的CG-Entrance服务到完成任务的持久化(PS-JobHistory)以及任务的各种拦截器处理(危险语法、变量替换、参数检查)等步骤,并做生产者消费者的并发控制;
- 准备阶段:任务在Entrance被Scheduler消费调度给Orchestrator模块进行任务的编排、并向LinkisMaster完成EngineConn的申请,在这过程中会对租户的资源进行管控;
- 执行阶段:任务从Orchestrator提交给EngineConn执行,EngineConn具体提交底层引擎进行执行,并实时将任务的信息推送给调用方;
- 结果返回阶段:向调用方返回结果,支持json和io流返回结果集
Linkis的整体任务执行架构如下图所示:
二、任务执行流程介绍
首先我们先对OLAP型任务的处理流程进行一个简要介绍,任务整体的一个执行流程如下图所示:
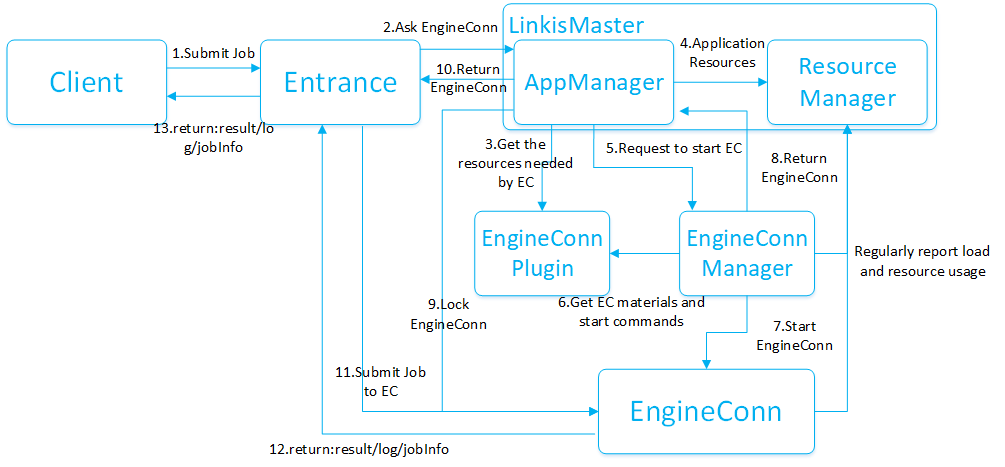
整个任务涉及到了所有的计算治理的所有服务,任务通过Gateway转发到Linkis的人口服务Entrance后,会通过对任务的标签进行多级调度(生产者消费者模式)通过FIFO的模式完成任务的调度执行,Entrance接着将任务提交给Orchestrator进行任务编排和提交,Orchestrator会向LinkisMaster完成EC的申请,在这过程中会通过任务的Label进行资源管控和引擎版本选择申请不同的EC。接着Orchestrator将编排后的任务提交给EC进行执行,EC会将job的日志、进度、资源使用等信息推动给Entrance服务,并推送给调用方。下面我们基于上图和结合任务的四个阶段(提交、准备、执行、返回)对任务的执行流程进行一个简要介绍。
2.1 Job提交阶段
Job提交阶段Linkis支持多种类型的任务:SQL, Python, Shell, Scala, Java等,支持不同的提交接口,支持Restful/JDBC/Python/Shell等提交接口。提交任务主要包含任务代码、标签、参数等信息即可,下面是一个RestFul的示例: 通过Restfu接口发起一个Spark Sql任务
"method": "/api/rest_j/v1/entrance/submit",
"data": {
"executionContent": {
"code": "select * from table01",
"runType": "sql"
},
"params": {
"variable": {// task variable
"testvar": "hello"
},
"configuration": {
"runtime": {// task runtime params
"jdbc.url": "XX"
},
"startup": { // ec start up params
"spark.executor.cores": "4"
}
}
},
"source": { //task source information
"scriptPath": "file:///tmp/hadoop/test.sql"
},
"labels": {
"engineType": "spark-2.4.3",
"userCreator": "hadoop-IDE"
}
}
- 任务首先会提交给Linkis的网关linkis-mg-gateway服务,Gateway会通过任务中是否带有routeLabel来转发给对应的Entrance服务,如果没有RouteLabel则随机转发给一个Entrance服务
- Entrance接受到对应的Job后,会调用PES中JobHistory模块的RPC对Job的信息进行持久化,并对参数和代码进性解析对自定义变量进行替换,并提交给调度器(默认FIFO调度)调度器会通过任务的标签进行分组,标签不同的任务互相不影响调度。
- Entrance在通过FIFO调度器消费后会提交给Orchestrator进行编排执行,就完成了任务的提交阶段 主要涉及的类简单说明:
EntranceRestfulApi: 入口服务的Controller类,任务提交、状态、日志、结果、job信息、任务kill等操作
EntranceServer:任务的提交入口,完成任务的持久化、任务拦截解析(EntranceInterceptors)、提交给调度器
EntranceContext:Entrance的上下文持有类,包含获取调度器、任务解析拦截器、logManager、持久化、listenBus等方法
FIFOScheduler: FIFO调度器,用于调度任务
EntranceExecutor:调度的执行器,任务调度后会提交给EntranceExecutor进行执行
EntranceJob:调度器调度的job任务,通过EntranceParser解析用户提交的JobRequest进行生成和JobRequest一一对应
此时任务状态为排队状态
2.2 Job准备阶段
Entrance的调度器,会按照Job中的Label生成不同的消费器去消费任务,任务被消费修改状态为Running时开始进入准备状态,到对应的任务后就是任务的准备阶段开始了。主要涉及以下几个服务:Entrance、LinkisMaster、EnginepluginServer、EngineConnManager、EngineConn,下面将对以下服务进行分开介绍。
2.2.1 Entrance步骤:
- 消费器(FIFOUserConsumer)通过对应标签配置的支持并发数进行消费将任务消费调度给编排器(Orchestrator)进行执行
- 首先是Orchestrator对提交的任务进行编排,对于普通的hive和Spark单引擎的任务主要是任务的解析、label检查和校验,对于多数据源混算的场景会拆分不同的任务提交给不同的数据源进行执行等
- 在准备阶段,编排器Orchestrator另外一个重要的事情是通过请求LinkisMaster获取用于执行任务的EngineConn。如果LinkisMaster有对应的EngineConn可以复用则直接返回,如果没有则创建EngineConn。
- Orchestrator拿到任务后提交给EngineConn进行执行,准备阶段结束,进入Job执行阶段 主要涉及的类简单说明:
## Entrance
FIFOUserConsumer: 调度器的消费器,会根据标签生成不同的消费器,如IDE-hadoop、spark-2.4.3生成不同的消费器。消费提交的任务。并控制同时运行的任务个数,通过对应标签配置的并发数:wds.linkis.rm.instance
DefaultEntranceExecutor:任务执行的入口,发起编排器的调用:callExecute
JobReq: 编排器接受的任务对象,通过EntranceJob转换而来,主要包括代码、标签信息、参数等
OrchestratorSession:类似于SparkSession,是编排器的入口。正常单例。
Orchestration:JobReq被OrchestratorSession编排后的返回对象,支持执行和打印执行计划等
OrchestrationFuture: Orchestration选择异步执行的返回,包括cancel、waitForCompleted、getResponse等常用方法
Operation:用于扩展操作任务的接口,现在已经实现了用于获取日志的LogOperation、获取进度的ProgressOperation等
## Orchestrator
CodeLogicalUnitExecTask: 代码类型任务的执行入口,任务最终编排运行后会调用该类的execute方法,首先会向LinkisMaster请求EngineConn再提交执行
DefaultCodeExecTaskExecutorManager:负责管控代码类型的EngineConn,包括请求和释放EngineConn
ComputationEngineConnManager:负责LinkisMaster进行对接,请求和释放ENgineConn
2.2.2 LinkisMaster步骤:
1.LinkisMaster接受到Entrance服务发出的请求EngineConn请求进行处理 2.判断是否有对应Label可以复用的EngineConn,有则直接返回 3.如果没有则进入创建EngineConn流程:
- 首先通过Label选择合适的EngineConnManager服务。
- 接着通过调用EnginePluginServer获取本次请求EngineConn的资源类型和资源使用,
- 通过资源类型和资源,判断对应的Label是否还有资源,如果有则进入创建,否则抛出重试异常
- 请求第一步的EngineConnManager启动EngineConn
- 等待EngineConn空闲,返回创建的EngineConn,否则判断异常是否可以重试
4.锁定创建的EngineConn返回给Entrance,注意这里为异步请求Entrance发出EC请求后会接受到对应的请求ID,LinkisMaster请求完毕后主动通过给对应的Entrance服务
主要涉及的类简单说明:
## LinkisMaster
EngineAskEngineService: LinkisMaster负责处理引擎请求的处理类,主要逻辑通过调用EngineReuseService判断是否有EngineConn可以复用,否则调用EngineCreateService创建EngineConn
EngineCreateService:负责创建EngineConn,主要几个步骤:
## LinkisEnginePluginServer
EngineConnLaunchService:提供ECM获取对应引擎类型EngineConn的启动信息
EngineConnResourceFactoryService:提供给LinkisMaster获取对应本次任务所需要启动EngineConn需要的资源
EngineConnResourceService: 负责管理引擎物料,包括刷新和刷新所有
## EngineConnManager
AbstractEngineConnLaunchService:负责启动接受LinkisMaster请求启动EngineConn的请求,并完成EngineConn引擎的启动
ECMHook: 用于处理EngineConn启动前后的前置后置操作,如hive UDF Jar加入到EngineConn启动的classPath中
这里需要说明的是如果用户存在一个可用空闲的引擎,则会跳过1,2,3,4 四个步骤;
2.3 Job执行阶段
当Entrance服务中的编排器拿到EngineConn后就进入了执行阶段,CodeLogicalUnitExecTask会将任务提交给EngineConn进行执行,EngineConn会通过对应的CodeLanguageLabel创建不同的执行器进行执行。主要步骤如下:
- CodeLogicalUnitExecTask通过RPC提交任务给到EngineConn
- EngineConn判断是否有对应的CodeLanguageLabel的执行器,如果没有则创建
- 提交给Executor进行执行,通过链接到具体底层的引擎执行进行执行,如Spark通过sparkSession提交sql、pyspark、scala任务
- 任务状态流转实时推送给Entrance服务
- 通过实现log4jAppender,SendAppender通过RPC将日志推送给Entrance服务
- 通过定时任务实时推送任务进度和资源信息给到Entrance
主要涉及的类简单说明:
ComputationTaskExecutionReceiver:Entrance服务端编排器用于接收EngineConn所有RPC请求的服务类,负责接收进度、日志、状态、结果集在通过ListenerBus的模式推送给上次调用方
TaskExecutionServiceImpl:EngineConn接收Entrance所有RPC请求的服务类,包括任务执行、状态查询、任务Kill等
ComputationExecutor:具体的任务执行父类,比如Spark分为SQL/Python/Scala Executor
ComputationExecutorHook: 用于Executor创建前后的Hook,比如初始化UDF、执行默认的UseDB等
EngineConnSyncListener: ResultSetListener/TaskProgressListener/TaskStatusListener 用于监听Executor执行任务过程中的进度、结果集、和进度等信息
SendAppender: 负责推送EngineConn端的日志给到Entrance
2.4 Job结果推送阶段
该阶段比较简单,主要用于将任务在EngineConn产生的结果集返回给Client,主要步骤如下:
- 首先在EngineConn执行任务过程中会进行结果集写入,写入到文件系统中获取到对应路径。当然也支持内存缓存,默认写文件
- EngineConn将对应的结果集路径和结果集个数返回给Entrance
- Entrance调用JobHistory将结果集路径信息更新到任务表中
- Client通过任务信息获取到结果集路径并读取结果集 主要涉及的类简单说明:
EngineExecutionContext:负责创建结果集和推送结果集给到Entrance服务
ResultSetWriter:负责写结果集到文件系统中支持linkis-storage支持的文件系统,现在以及支持本地和HDFS。支持的结果集类型,表格、文本、HTML、图片等
JobHistory:存储有任务的所有信息包括状态、结果路径、指标信息等对应DB中的实体类
ResultSetReader:读取结果集的关键类
三、总结
上面我们主要介绍了Linkis计算治理服务组CGS的OLAP任务的整个执行流程,按照任务请求的处理过程对任务拆分成了提交、准备、执行、返回结果四个阶段。CGS主要就是遵循这4个阶段来设计实现的,服务于这4个阶段,且为每个阶段提供了强大和灵活的能力。在提交阶段,主要提供通用的接口,接收上层应用工具提交过来的任务,并能提供基础的解析和拦截能力;在准备阶段,主要通过编排器Orchestrator和LinkisMaster完成对任务的解析编排,并且做资源控制和完成EngineConn的创建;执行阶段,通过引擎连接器EngineConn来去实际完成和底层引擎的对接,通常每个用户要连接不同的底层引擎,就得先启动一个对应的底层引擎连接器EC。计算任务通过EC来提交给底层引擎做实际的执行和状态、日志、结果等信息的获取,及在结果返回阶段,返回任务执行的结果信息,支持按照多种返回模式,如:文件流、JSON、JDBC等。整体的时序图如下: