常见问题
Linkis1.0常见问题和解决办法:https://docs.qq.com/doc/DWlN4emlJeEJxWlR0
一、使用问题
Q1: linkis的ps-cs服务日志报这个错: figServletWebServerApplicationContext (559)
[refresh] - Exception encountered during context initi
alization - cancelling refresh attempt: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'eurekaInstanceLabelClient': Invocation of initkaba method failed; nested exception is java.lang.RuntimeException: com.netflix.client.ClientException: Load balancer does not have available server for client: linkis-ps-publicservice
A:这个是因为publicservice服务没有启动成功导致,建议手动重启下publicservice sh/sbin/linkis-dameo.sh restart ps-publicservice
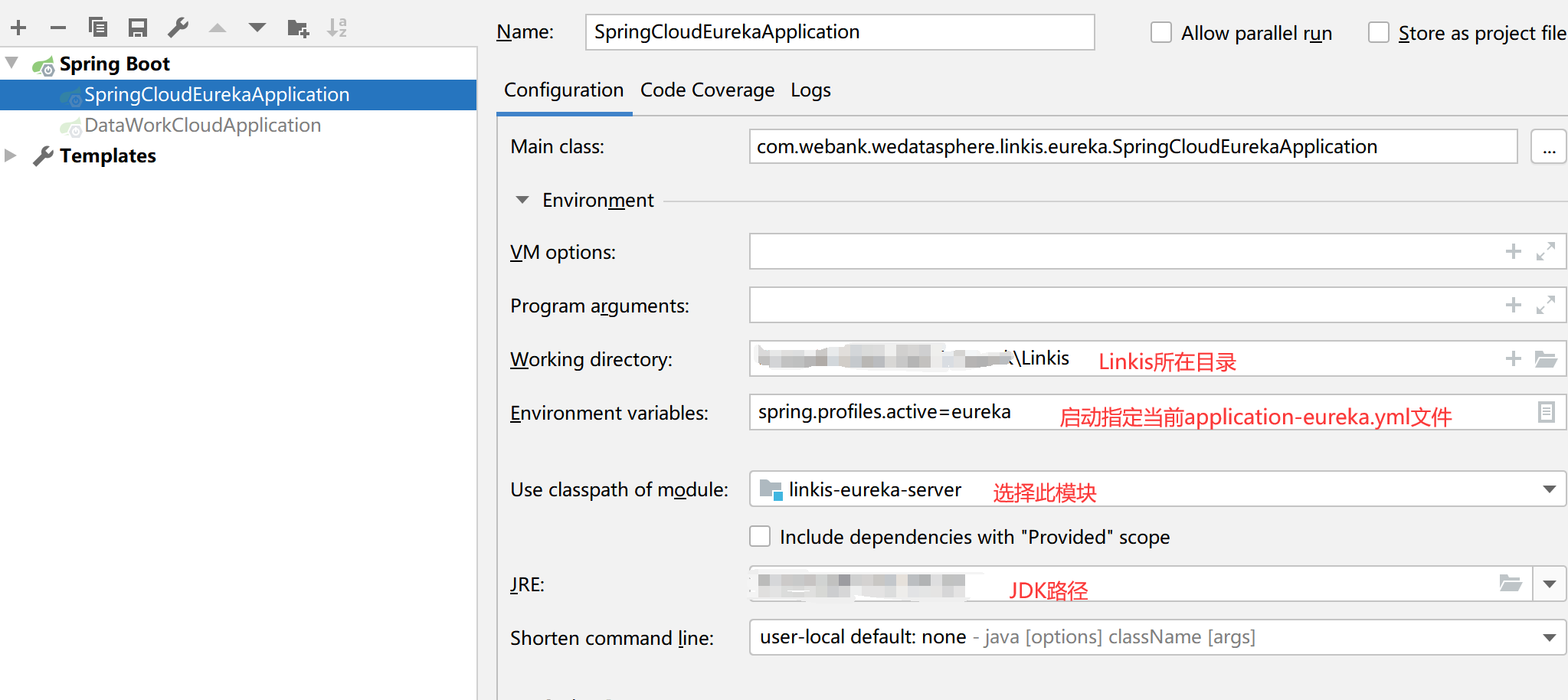
Q2: Linkis-eureka调试说明
A: 如需要调试eureka程序,需要先进行一些配置,如下图
application-eureka.yml需要去掉部分注释配置,正常启动配置如下图:
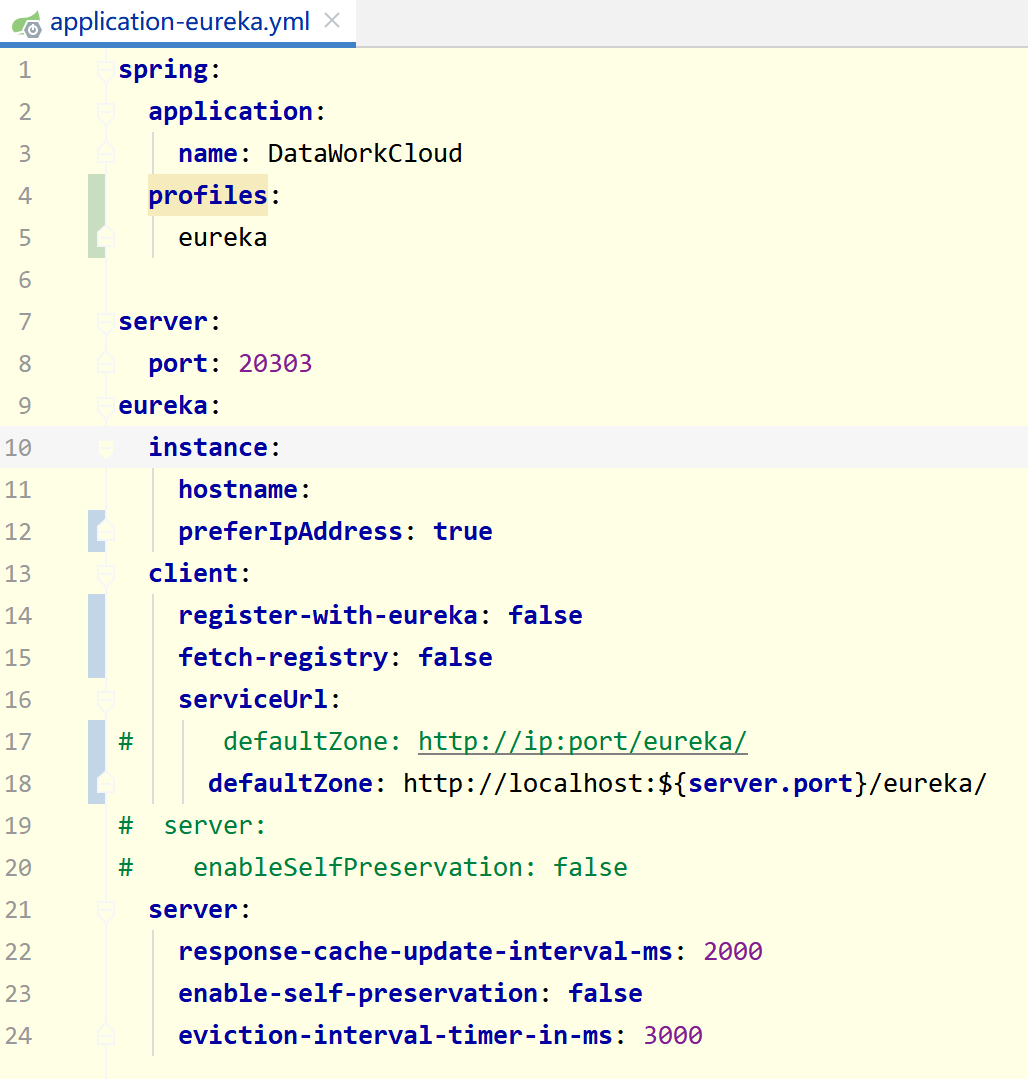
Q3: eureka 第一次启动 自动停止,需要手工重新启动的问题
A: 这个是因为eureka的启动Java进程时没有使用nohup当会话退出后,被操作系统自动清理了任务,需要修改下eureka的启动脚本,加上nohup:

可以参考PR:https://github.com/apache/linkis/pull/837/files
Q4: Linkis Entrance LogWriter 缺依赖包
A: Hadoop 3需修改linkis-hadoop-common pom文件,详见:https://linkis.apache.org/zh-CN/docs/next/development/linkis-compile-and-package/
Q5: Linkis1.0执行任务时,ECP服务抛出如下错误:Caused by: java.util.NoSuchElementException: None.get?
错误详细日志:
解决办法: 这个时因为对应引擎版本物料没有在数据库表中存在对应的记录,可能时ecp服务启动的时候有误导致,您可以重启下ecp服务,看是否在上传BML的时候存在错误,对应的表为:linkis_cg_engine_conn_plugin_bml_resources
Q6: Linkis1.X提示资源不足的通用排查方法
资源不足分为两种情况:
- 服务器本身的资源不足
- 用户自身的资源不足(linkis会对用户资源进行管控)。 这两种资源在linkis1.X中都记录在linkis_cg_manager_label_resource和linkis_cg_manager_linkis_resource中,前者为label和resource的关联表,后者为resource表 通常情况下,linkis1.0对资源的高并发管控是安全的,不建议通过修改表记录的方式去强行重置用户资源记录。但是由于安装调试过程中,linkis的执行环境有所不同,所以会出现引擎启动失败,或在引擎启动过程中对微服务的反复重启导致资源没有安全释放,或者监控器没来得及自动清理(有小时级的延迟),就可能会出现资源不足的问题,严重时会导致用户的大部分资源处于上锁状态。因此对于排查资源不足可以参考以下步骤: a.在管理台确认ECM的剩余资源是否大于引擎的请求资源,如果ECM剩余的资源非常少,那么就会导致请求新的引擎失败,需要手动在ECM中关掉部分闲置的引擎,linkis对引擎也有闲时自动释放的机制,但这个时间默认设置的相对较长。 b.如果ECM资源充足,则必定是用户剩余资源不足以请求新的引擎,首先确定用户的执行任务时产生的label标签,例如用户hadoop在Scriptis上执行spark2.4.3脚本,则在linkis_cg_manager_label表中对应下条记录 我们拿到这条label的id值,在关联表linkis_cg_manager_label_resource中找到对应的resourceId,通过resourceId在linkis_cg_manager_linkis_resource中就能找到对应的label的resource记录,可以检查下这条记录中的剩余资源
如果这条资源排查判定是异常情况,即不符合实际引擎启动产生的资源。可以进行以下操作恢复: 在确认该label下所有引擎已经关停的情况下,可以将这条资源和关联表linkis_cg_manager_label_resource对应的关联记录直接删除,再次请求时则会自动重置这条资源。 注意:该label所有引擎已经关停在上个例子中是指的hadoop用户在Scriptis上启动的spark2.4.3的引擎已经全部关停,可以在管理台的资源管理中看到该用户启动的所有引擎实例。否则可能还会出现该label的资源记录异常。
Q7: linkis启动报错:NoSuchMethodErrorgetSessionManager()Lorg/eclipse/jetty/server/SessionManager
具体堆栈:
startup of context o.s.b.w.e.j.JettyEmbeddedWebAppContext@6c6919ff{application,/,[file:///tmp/jetty-docbase.9102.6375358926927953589/],UNAVAILABLE} java.lang.NoSuchMethodError: org.eclipse.jetty.server.session.SessionHandler.getSessionManager()Lorg/eclipse/jetty/server/SessionManager;
at org.eclipse.jetty.servlet.ServletContextHandler\$Context.getSessionCookieConfig(ServletContextHandler.java:1415) ~[jetty-servlet-9.3.20.v20170531.jar:9.3.20.v20170531]
解法:jetty-servlet 和 jetty-security版本需要从9.3.20升级为9.4.20;
二、环境问题
Q1: Linkis1.0 执行任务报: select list is not in group by clause
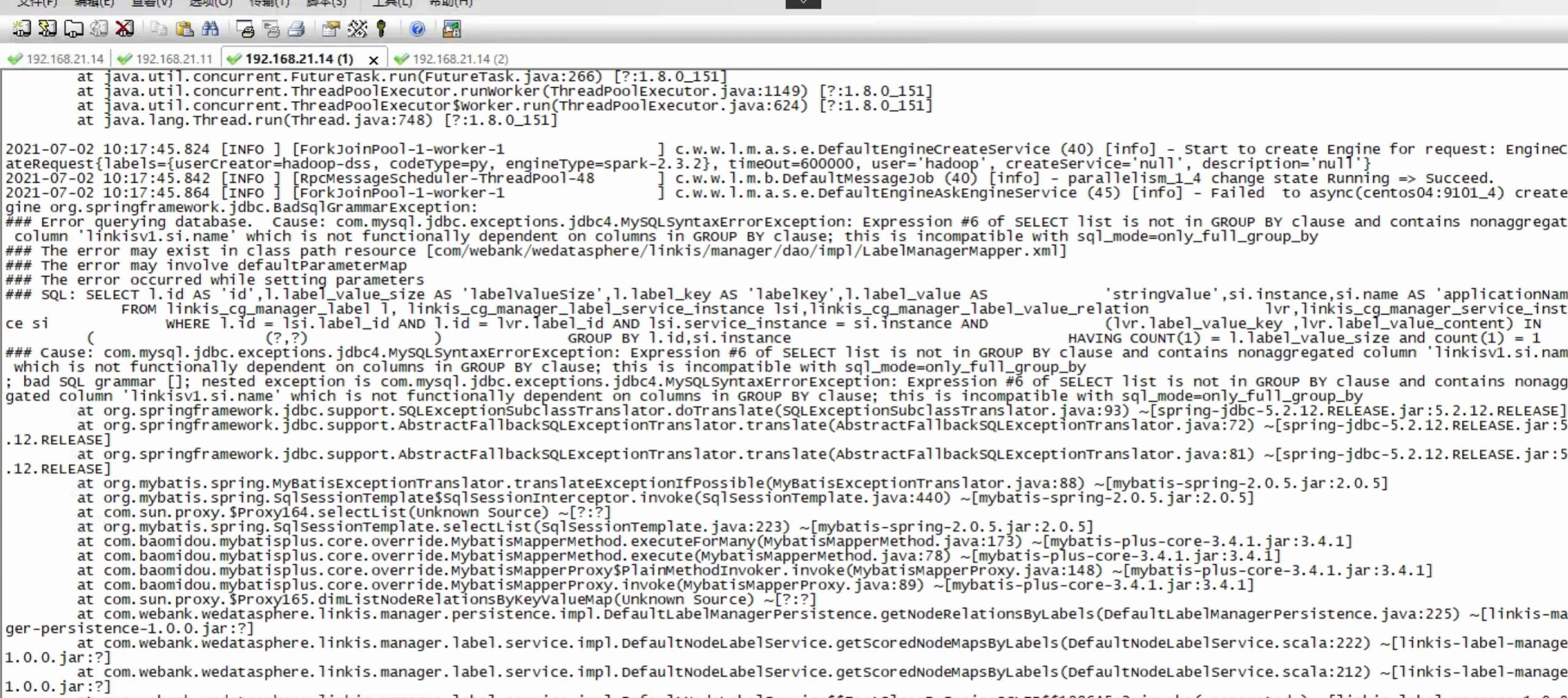
这个问题是在mysql 5.8版本时,由于全局设置的模式默认值导致,需要在mysql cli里面执行下这行就行:
SET GLOBAL sql_mode=(SELECT REPLACE(@@sql_mode,'ONLY_FULL_GROUP_BY',''));
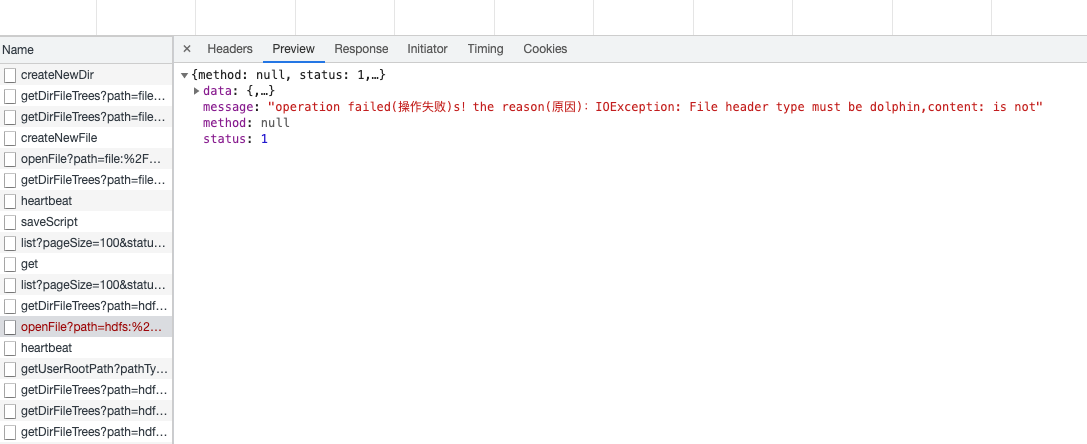
Q2: 部署后执行脚,执行命令,收集结果时,遇到这样的报错,IOException: File header type must be dolphin:
A:这个应该是重复安装导致的,导致结果集写到同一个文件里面了,之前的Linkis 0.X 版本采用的结果集写是append,1.0已经修改为新增了,可以清理下结果集的目录:配置参数为wds.linkis.resultSet.store.path,可以清理下这个目录
Q3: Spark版本不一致导致的json4s包冲突问题,报错如下:错误信息:caused by: java.lang.NoSuchMethodError: org.json4s.jackson.jsonMethod$
解决方案: 这个是因为Spark jars的json4s和lib/linkis-engineconn-plugins/spark/dist/version/lib 包里面的json4s版本不一致,官方发布release时会在后面注明Spark的支持版本,如果不一致会存在该问题。 解决办法将Spark jars里面的json4s的包替换掉lib/linkis-engineconn-plugins/spark/dist/version/lib 包里面的json4s版本。另外netty包也可能存在冲突,可按Json4s的方法进行处理.然后重启ecp服务即可:sh sbin/linkis-damon.sh restart cg-engineplugin
Q4: Linkis1.X在CDH5.16.1版本提交spark sql任务时,404的问题排查方法
主要报错信息如下:
21304, Task is Failed,errorMsg: errCode: 12003 ,desc: ip:port_x Failed to async get EngineNode FeignException.NotFound: status 404 reading RPCReceiveRemote#receiveAndReply(Message) ,ip: xxxxx ,port: 9104 ,serviceKind: linkis-cg-entrance
org.apache.jasper.servlet.JspServlet 89 warn - PWC6117: File "/home/hadoop/dss1.0/tmp/hadoop/workDir/7c3b796f-aadd-46a5-b515-0779e523561a/tmp/jetty-docbase.1802511762054502345.46019/api/rest_j/v1/rpc/receiveAndReply" not found
以上报错信息主要是由于cdh环境变量中的jar冲突导致的,需要查找org.apache.jasper.servlet.JspServlet这个类所在的jar包,本地cdh的环境变量路径为:/opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/jars,删除了该目录下面的对应的jasper-compile-${version}.jar和jsp-${version}.jar这两类jar包,服务不需要重启,即可重新运行spark sql任务,问题解决。
Q5: 运行报错缺包matplotlib
标准的python环境,需要安装好anaconda2和anaconda3,并且默认anaconda为anaconda2。这里面包含了常见大多数python库。
Q6: 启动微服务linkis-ps-cs时,报DebuggClassWriter overrides final method visit
具体异常栈:
解法:jar包冲突,删除asm-5.0.4. jar;
Q7: shell引擎调度执行时,引擎执行目录报如下错误/bin/java:No such file or directory:
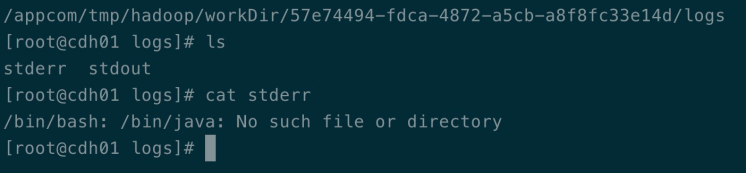
解法:本地java的环境变量有问题,需要对java命令做下符号链接。
Q8: hive引擎调度时,engineConnManager的错误日志如下method did not exist:SessionHandler:
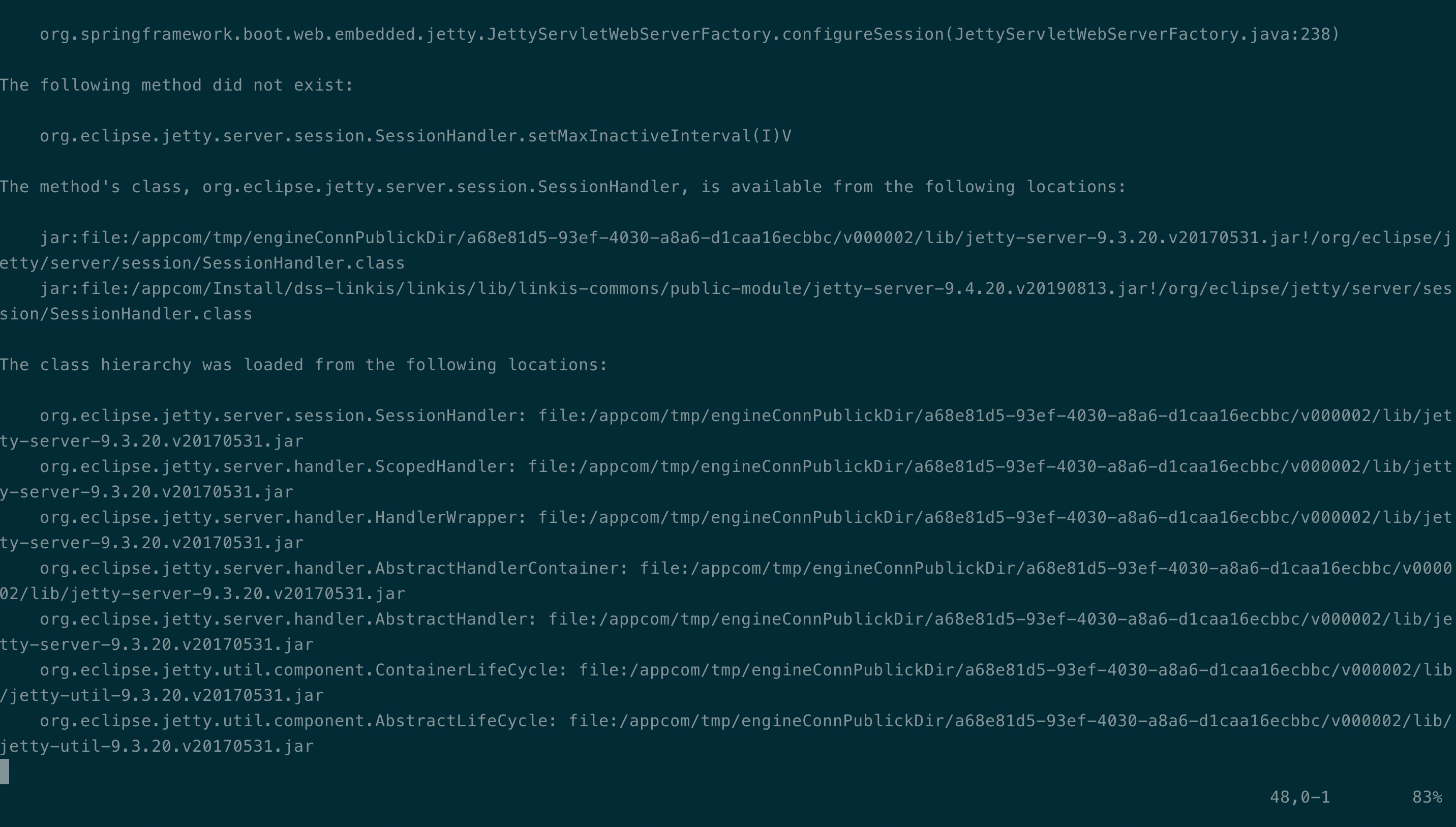
解法:hive引擎lib下,jetty jar包冲突,jetty-security、 jetty-server替换为9.4.20;
Q9: hive引擎执行时,报如下错误Lcom/google/common/collect/UnmodifiableIterator:
2021-03-16 13:32:23.304 ERROR [pool-2-thread-1]com.webank.wedatasphere.linkis.engineplugin.hive.executor.HiveEngineConnExecutor 140 run - query failed, reason : java.lang.AccessError: tried to access method com.google.common.collect.Iterators.emptyIterator() Lcom/google/common/collect/UnmodifiableIterator; from class org.apache.hadoop.hive.ql.exec.FetchOperator
at org.apache.hadoop.hive.ql.exec.FetchOperator.<init>(FetchOperator.java:108) ~[hive-exec-2.1.1-cdh6.1.0.jar:2.1.1-cdh6.1.0]
at org.apache.hadoop.hive.ql.exec.FetchTask.initialize(FetchTask.java:86) ~[hive-exec-2.1.1-cdh6.1.0.jar:2.1.1-cdh6.1.0]
at org.apache.hadoop.hive.ql..compile(Driver.java:629) ~[hive-exec-2.1.1-cdh6.1.0.jar:2.1.1-cdh6.1.0]
at org.apache.hadoop.hive.ql.Driver.compileInternal(Driver.java:1414) ~[hive-exec-2.1.1-cdh6.1.0.jar:2.1.1-cdh6.1.0]
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1543) ~[hive-exec-2.1.1-cdh6.1.0.jar:2.1.1-cdh6.1.0]
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1332) ~[hive-exec-2.1.1-cdh6.1.0.jar:2.1.1-cdh6.1.0]
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1321) ~[hive-exec-2.1.1-cdh6.1.0.jar:2.1.1-cdh6.1.0]
atcom.webank.wedatasphere.linkis.engineplugin.hive.executor.HiveEngineConnExecutor$$anon$1.run(HiveEngineConnExecutor.scala:152) [linkis-engineplugin-hive-dev-1.0.0.jar:?]
atcom.webank.wedatasphere.linkis.engineplugin.hive.executor.HiveEngineConnExecutor$$anon$1.run(HiveEngineConnExecutor.scala:126) [linkis-engineplugin-hive-dev-1.0.0.jar:?]
解法:guava包冲突,删除hive/dist/v1.2.1/lib下的guava-25.1-jre.jar;
Q10: 引擎调度时,报如下错误Python proces is not alive:

解法:服务器安装anaconda3 包管理器,经过对python调试,发现两个问题:(1)缺乏pandas、matplotlib模块,需要手动安装;(2)新版python引擎执行时,依赖python高版本,首先安装python3,其次做下符号链接(如下图),重启engineplugin服务。
Q11: spark引擎执行时,报如下错误NoClassDefFoundError: org/apache/hadoop/hive/ql/io/orc/OrcFile:
2021-03-19 15:12:49.227 INFO [dag-scheduler-event-loop] org.apache.spark.scheduler.DAGScheduler 57 logInfo -ShuffleMapStage 5 (show at <console>:69) failed in 21.269 s due to Job aborted due to stage failure: Task 1 in stage 5.0 failed 4 times, most recent failure: Lost task 1.3 in stage 5.0 (TID 139, cdh03, executor 6):java.lang.NoClassDefFoundError: org/apache/hadoop/hive/ql/io/orc/OrcFile
解法:cdh6.3.2集群spark引擎classpath只有/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark/jars,需要新增hive-exec-2.1.1-cdh6.1.0.jar,然后重启spark。
三、配置问题
Q1: Script 左侧数据库刷不出来
解决方案: a. 原因可能是linkis-metatdata服务没有读取到HIVE_CONF_DIR的错误,可以通过配置linkis-metadata的参数:对应为元数据库的JDBC连接串
hive.meta.url=
hive.meta.user=
hive.meta.password=
Q2: Scriptis的右侧刷不出来数据库,一直在刷新中(需要注意的是linkis的metadata暂时不支持对接sentry和Ranger只支持hive原生的权限控制),错误信息: 前端数据库tab一直处于刷新状态
解决方案: 这是因为右侧的数据库我们是限制了权限的,而这个依赖hive开启授权访问:
hive.security.authorization.enabled=true;
具体可以参考:https://blog.csdn.net/yancychas/article/details/84202400 开启如果配置了该参数还没有的话,那就需要给这个用户授予相应的库表权限,执行grant语句,可以参考相同的链接授权部分。
# 授权参考以hadoop为例:
# 进入hive client 查看hadoop用户数据库授权情况:
show grant user hadoop on database default;
# 给用户数据库授权情况:
grant all on database default to user hadoop;
如果不想开启权限控制,即每个用户都可以看到库表,可以修改:com/webank/wedatasphere/linkis/metadata/hive/dao/impl/HiveMetaDao.xml的sql去掉权限控制部分
Q3: [Scriptis][工作空间] 登录Scriptis时报根目录不存在,存在工作空间和HDFS两个跟目录:错误信息: 在登录进入后,前端弹出如下信息(用户本地目录不存在,请联系管理员添加)
解决方案:
- a.确认linkis-ps-publicservice的conf目录下linkis.properties参数:wds.linkis.workspace.filesystem.localuserrootpath=file:///tmp/linkis/ 是不是file://开头。
- b.确认wds.linkis.workspace.filesystem.hdfsuserrootpath.prefix=hdfs:///tmp/linkis/ 是不是hdfs://开头
- c.确认/tmp/linkis目录下是不是有用户目录,这里的用户是指前端登录用户,比如hadoop用户登录,那么要建立:/tmp/linkis/hadoop目录,如果目录存在确认目录权限登录用户可以操作,如果还是不行可以参考publicservice的报错,错误会说明权限还是路径问题
Q4: [管理台][设置]怎么调整任务使用的yarn队列?错误信息: 执行sql任务时报1.获取Yarn队列信息异常 或者 用户XX不能提交到队列
解决方案: 在前端—管理台—设置—通用设置—Yarn队列 配置登录用户有权限的队列
Q5: Hive查询的时候报:找不到zk相关的类比如:org.apache.curator.,错误信息: 执行hive任务时,日志报找不到org.apache.curator.开头的类,classNotFound
解决方案: 这是因为开启了hive事务,可以在linkis的机器上面修改hive-site.xml关掉事务配置,参考hive事务:https://www.jianshu.com/p/aa0f0fdd234c 或者将相关包放到引擎插件目录中lib/linkis-engineconn-plugins/hive/dist/version/lib
Q6: Linkis如何支持kerberos
解决方案: 在linkis中获取Hadoop的FileSystem都是通过HDFSUtils类进行实现的,所以我们将kerberos放在该类,用户可以看下该类的逻辑,现在支持的登录模式如下:
if(KERBEROS_ENABLE.getValue) {
val path = new File(
TAB_FILE.getValue , userName + ".keytab").getPath
val user = getKerberosUser(userName)
UserGroupInformation.setConfiguration(getConfiguration(userName))
UserGroupInformation.loginUserFromKeytabAndReturnUGI(user, path)
} else {
UserGroupInformation.createRemoteUser(userName)
}
用户只要在配置文linkis.properties配置以下参数即可:
wds.linkis.keytab.enable=true
wds.linkis.keytab.file=/appcom/keytab/ #keytab放置目录,该目录存储的是多个用户的username.keytab的文件
wds.linkis.keytab.host.enabled=false #是否带上principle客户端认证
wds.linkis.keytab.host=127.0.0.1 #principle认证需要带上的客户端IP
Q7: 关于Linkis除了支持部署用户登录可以配置其他用户登录吗?
解决方案: 当然可以。部署用户只是为了方便使用的用户。linkis-mg-gateway支持通过配置LDAP服务和SSO服务进行访问,本身没有用户校验体系,比如要开启LDAP服务访问,你只要在配置linkis-mg-gateway.properties您的LDAP服务端的配置如下:
wds.linkis.ldap.proxy.url=ldap://127.0.0.1:1389/#您的LDAP服务URL
wds.linkis.ldap.proxy.baseDN=dc=webank,dc=com#您的LDAP服务的配置
用户如果需要执行任务,还需在linux服务器上面建立相应用户名的用户,如果是标准版本该用户需要能执行Spark和hive任务,并需要在本地工作空间和HDFS目录/tmp/linkis建立对应的用户名目录。
Q8: Linkis管理台,管理员页面ECM和微服务管理怎么 开启?

解决方案:需要在conf/linkis.properties文件里面设置管理员:
wds.linkis.governance.station.admin=hadoop,peacewong
设置完成后,重启下publicservice服务即可
Q9: 启动微服务linkis-ps-publicservice时,kJdbcUtils.getDriverClassName NPE
具体异常栈:ExternalResourceProvider
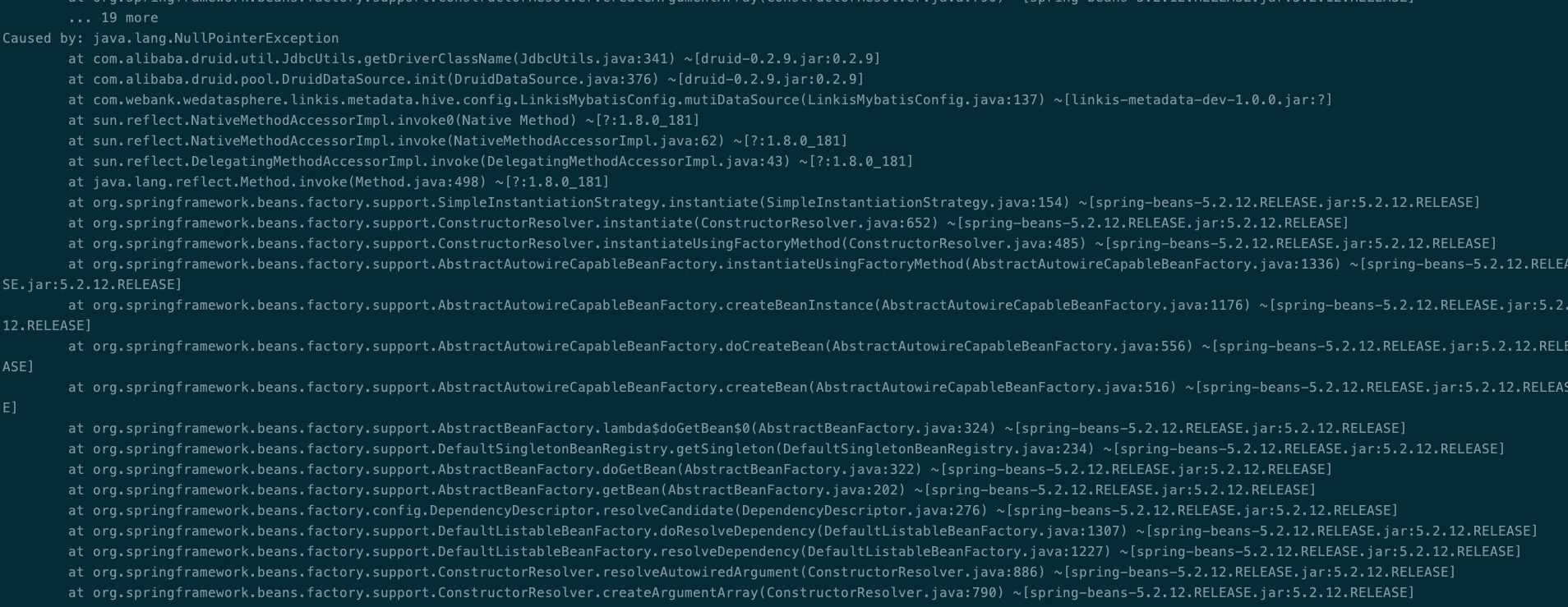
解法:linkis-ps-publicservice配置问题导致的,修改linkis.properties hive.meta开头的三个参数:
Q10: hive引擎调度时,报如下错误EngineConnPluginNotFoundException:errorCode:70063
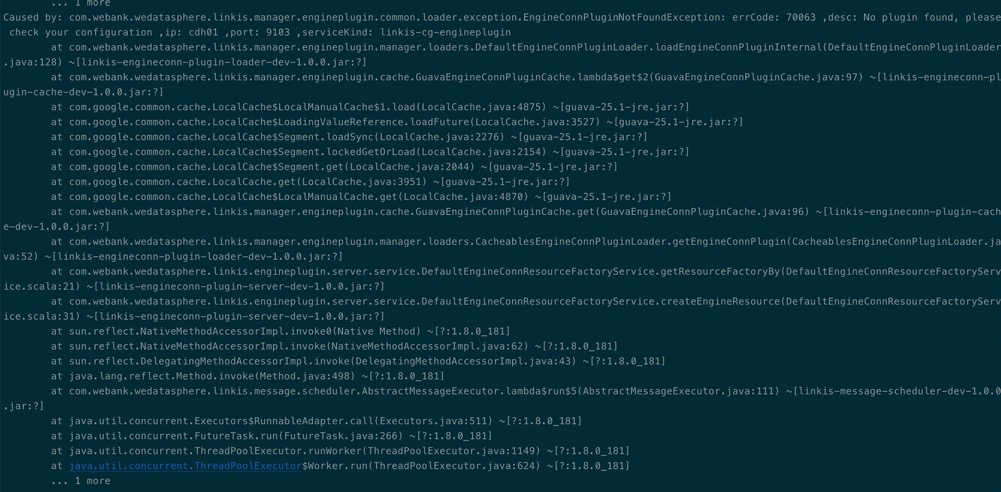
解法:安装的时候没有修改对应引擎的Version导致,所以默认插入到db里面的引擎类型为默认版本,而编译出来的版本不是默认版本导致。
具体修改步骤:
cd /appcom/Install/dss-linkis/linkis/lib/linkis-engineconn-plugins/,
修改dist目录下的v2.1.1 目录名 修改为v1.2.1
修改plugin目录下的子目录名2.1.1 为 默认版本的1.2.1
如果是Spark需要相应修改dist/2.4.3 和plugin/2.4.3
最后重启engineplugin服务。
Q11: hive引擎调度执行时,报错如下opertion failed NullPointerException:
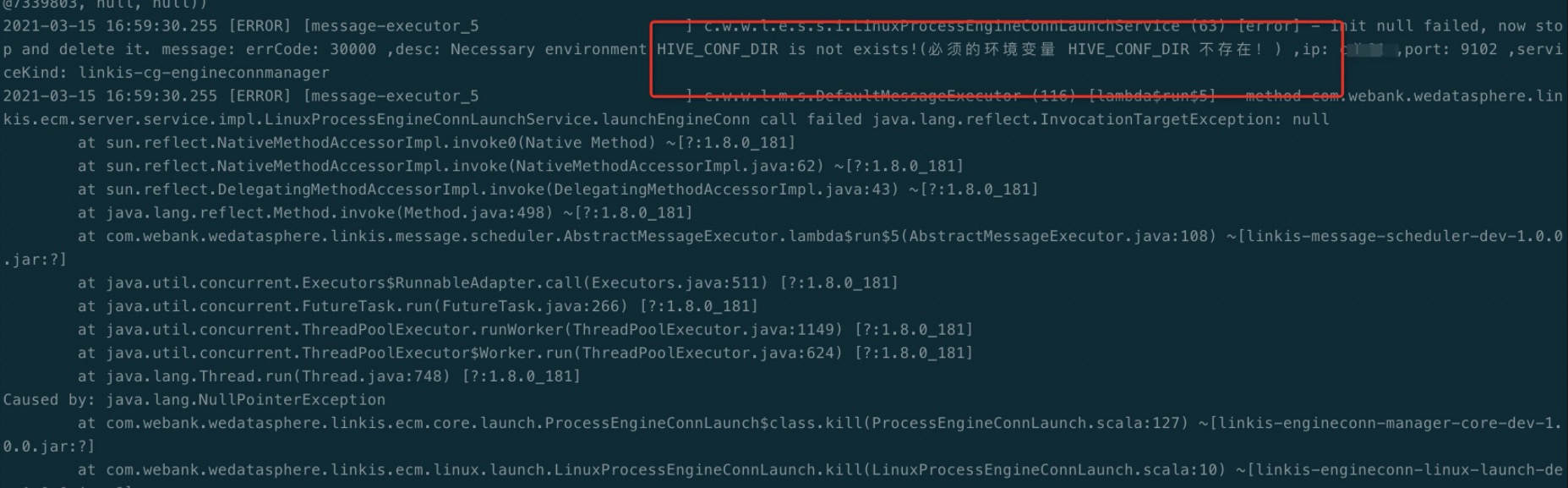
解法:服务器缺少环境变量,/etc/profile增加export HIVE_CONF_DIR=/etc/hive/conf;
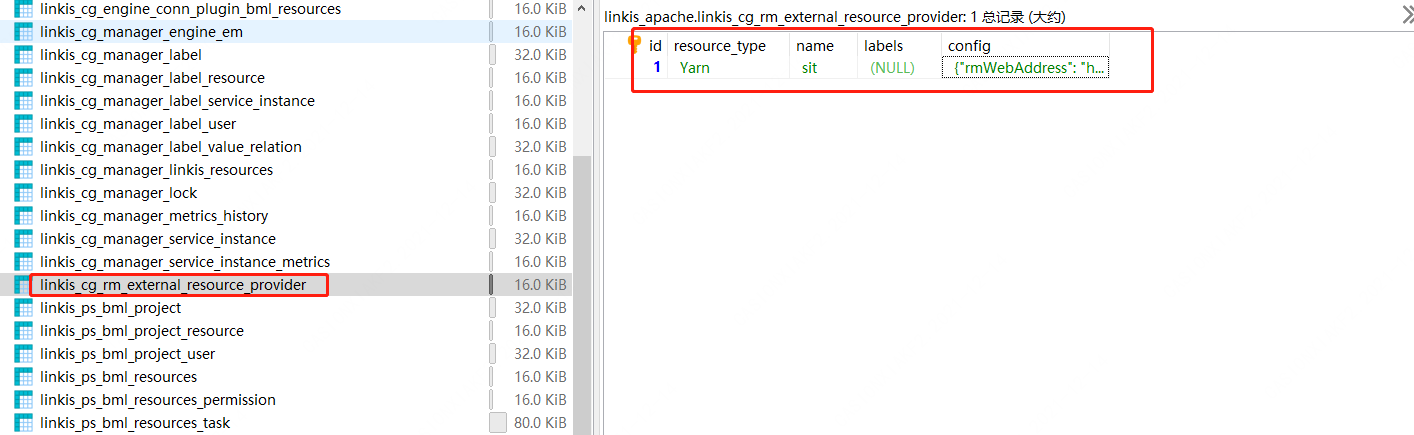
Q12: spark引擎启动时,报错 get the queue information excepiton.(获取Yarn队列信息异常)以及http链接异常
解法:yarn的地址配置迁移DB配置,需要增加如下配置:
INSERT INTO `linkis_cg_rm_external_resource_provider` (`resource_type`, `name`, `labels`, `config`) VALUES ('Yarn', 'default', NULL, '{\r\n"rmWebAddress": "http://xxip:xxport",\r\n"hadoopVersion": "2.7.2",\r\n"authorEnable":true,\r\n"user":"hadoop",\r\n"pwd":"xxxx"\r\n}');
config 字段示例
{
"rmWebAddress": "http://127.0.0.1:8080",
"hadoopVersion": "2.7.2",
"authorEnable":true,
"user":"hadoop",
"pwd":"passwordxxx"
}
Q13: pythonspark调度执行,报错:initialize python executor failed ClassNotFoundException org.slf4j.impl.StaticLoggerBinder
具体 如下:

解法:原因是spark服务端缺少 slf4j-log4j12-1.7.25.jar,copy上述jar报到/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark/jars。
Q14: 常见包冲突问题:
java.lang.NoSuchMethodError: javax.ws.rs.core.Application.getProperties()Ljava/util/Map; 冲突包为:jsr311-api-1.1.1.jar也有可能jessery冲突
java.lang.BootstrapMethodError: java.lang.NoSuchMethodError: javax.servlet.ServletContext.setInitParameter(Ljava/lang/String;Ljava/lang/String;)Z
冲突包为:servlet-api.jar
org/eclipse/jetty/util/processorUtils 冲突包为:jetty-util-9.4.11.v20180605.jar 这个是正确版本
java.lang.NoClassDefFoundError: Could not initialize class dispatch.Http$
冲突包为需要拷入:netty-3.6.2.Final.jar
hive-exec带入的其他jar导致的冲突calcite-avatica-1.6.0.jar也有可能带入jackson包的冲突,导致com.fasterxml.jackson.databind相关的错误 Cannot inherit from final class 是因为calcite-avatica-1.6.0.jar导致
LZO压缩问题hadoop-lzo的jar 7.org.eclipse.jetty.server.session.SessionHandler.getSessionManager()Lorg/eclipse/jetty/server/SessionManager; 需要将冲突包:jetty-servlet 和 jetty-security 替换为9.4.20
Q15: 运行Scripts的Mysql脚本报错\sql引擎报错
MYSQL脚本:运行sql报错:
com.webank.wedatasphere.linkis.orchestrator.ecm.exception.ECMPluginErrorException: errCode: 12003 ,desc: localhost:9101_0 Failed to async get EngineNode RMErrorException: errCode: 11006 ,desc: Failed to request external resourceClassCastException: org.json4s.JsonAST$JNothing$ cannot be cast to org.json4s.JsonAST$JString ,ip: localhost ,port: 9101 ,serviceKind: linkis-cg-linkismanager ,ip: localhost ,port: 9104 ,serviceKind: linkis-cg-entrance
at com.webank.wedatasphere.linkis.orchestrator.ecm.ComputationEngineConnManager.getEngineNodeAskManager(ComputationEngineConnManager.scala:157) ~[linkis-orchestrator-ecm-plugin-1.0.2.jar:?]
解决办法:linkis_cg_rm_external_resource_provider表修改正确的yarn地址
Q16: scriptis执行脚本等待时间长

scriptis执行脚本等待时间长,报错Failed to async get EngineNode TimeoutException: 解决办法:可以检查linkismanager的日志,一般是因为引擎启动超时
Q17: scriptis执行jdbc脚本,报错
scriptis执行jdbc脚本,报错
Failed to async get EngineNode ErrorException: errCode: 0 ,desc: operation failed(操作失败)s!the reason(原因):EngineConnPluginNotFoundException: errCode: 70063 ,desc: No plugin foundjdbc-4please check your configuration
解决办法 需要安装下对应的引擎插件,可以参考:引擎安装指引
Q18: 关闭资源检查
报错现象:资源不足 linkismanager服务修改下这个配置:wds.linkis.manager.rm.request.enable=false 可以清理下资源记录,或者设置小点的资源 或者关闭检测 linkismanager服务修改下这个配置:wds.linkis.manager.rm.request.enable=false
Q19: 执行脚本报错
GatewayErrorException: errCode: 11012 ,desc: Cannot find an instance in the routing chain of serviceId [linkis-cg-entrance], please retry ,ip: localhost ,port: 9001 ,serviceKind: linkis-mg-gateway

A:请检查linkis-cg-entrance服务是否正常启动。
Q20: ScriptIs执行脚本 TimeoutException
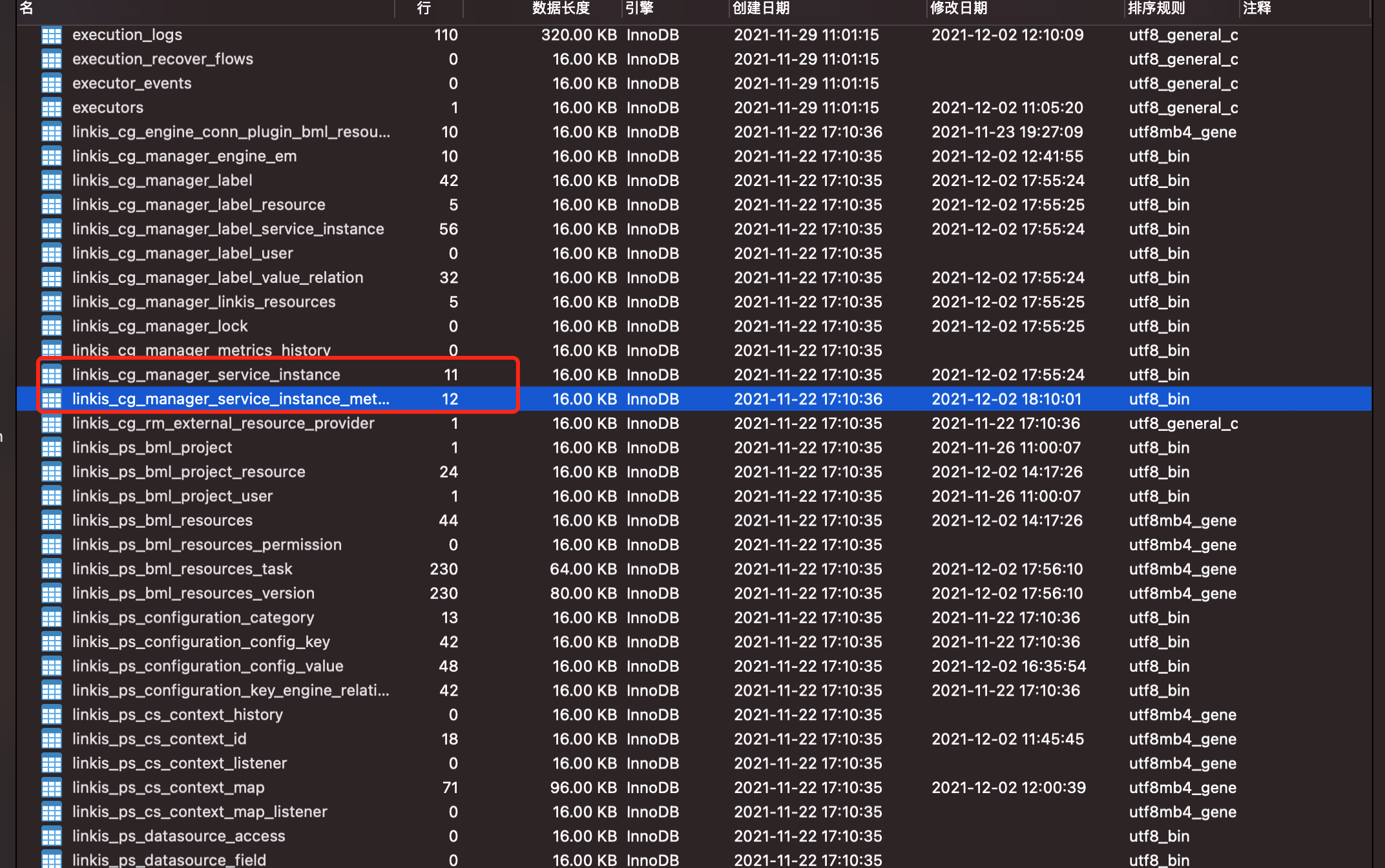
linkis-cg-linkismanager.log中, 重复打印Need a ServiceInstance(linkis-cg-entrance, localhost:9104), but cannot find in DiscoveryClient refresh list. 这是因为实例被强制关闭了,而数据库当中持久化认为这个实例还存在导致的,解决方案是停止服务后,清空 linkis_cg_manager_service_instance 和 linkis_cg_manager_service_instance_metrics 这两张表。
Q21: 引擎超时时间设置
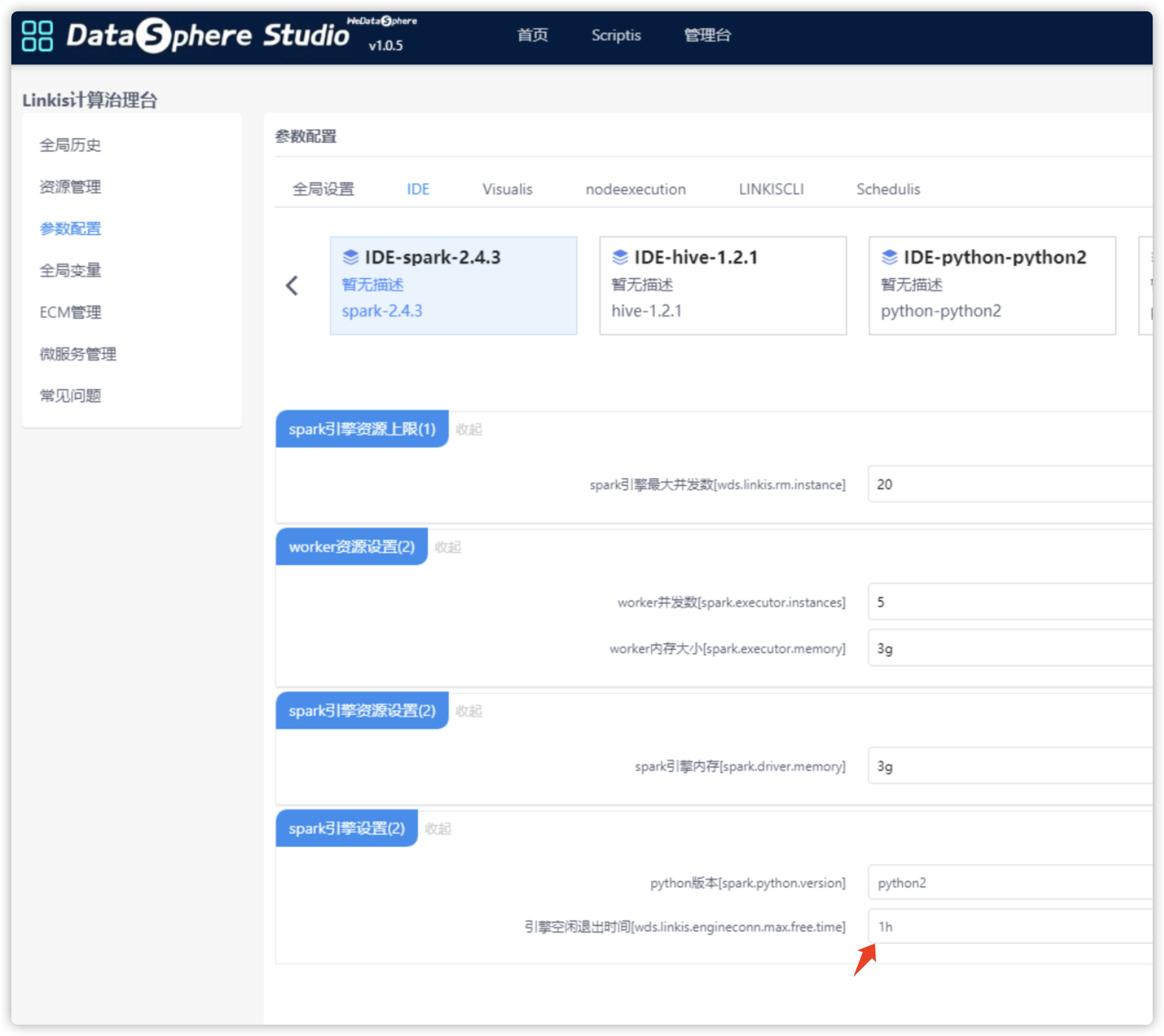
①管理台参数配置,可以对应引擎参数,可以修改超时时间。保存后kill现有引擎即可。 ②如未显示超时配置,需要手动修改 linkis-engineconn-plugins目录下,对应引擎插件目录 如 spark/dist/v2.4.3/conf/linkis-engineconn.properties ,默认配置 wds.linkis.engineconn.max.free.time=1h ,表示1h超时,可带单位m 、h。0表示不超时,不会自动kill。改完需要重启ecp,并且kill现有引擎,跑新任务起引擎即可生效。
Q22: 新建工作流的时候,提示“504 Gateway Time-out”
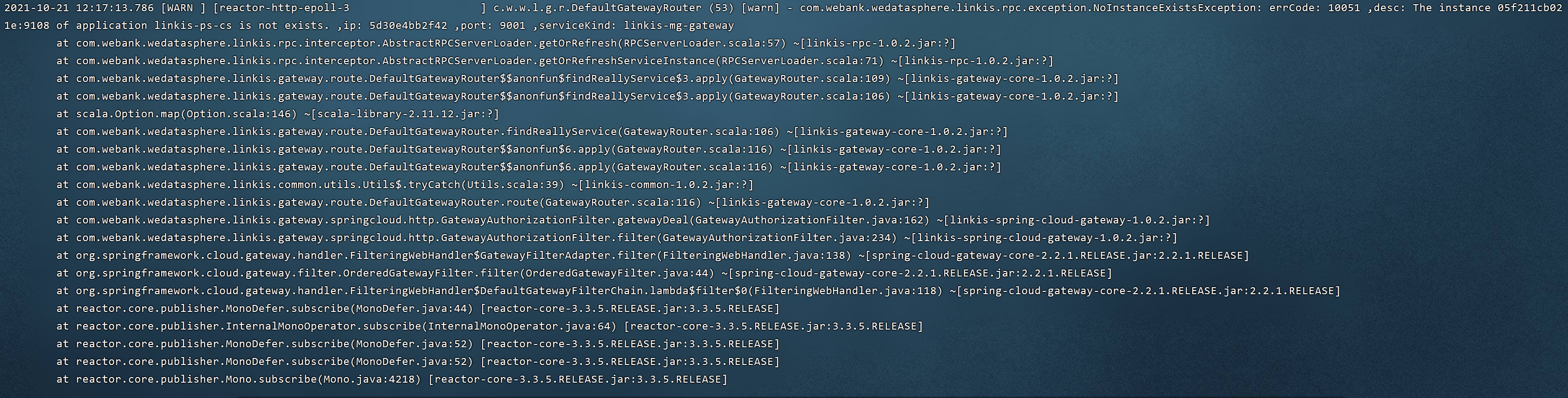
错误信息:The instance 05f211cb021e:9108 of application linkis-ps-cs is not exists. ,ip: 5d30e4bb2f42 ,port: 9001 ,serviceKind: linkis-mg-gateway,如下图:
Q23: Scripts执行python脚本(脚本内容是很简单的print)正常执行成功,通过任务调度系统也可以执行成功,通过作业流的编辑作业脚本页面也可执行成功,但是通过作业流执行时报错
错误信息:
You can go to this path(/opt/kepler/work/engine/hadoop/workDir/9c28976e-63ba-4d9d-b85e-b37d84144596/logs) to find the reason or ask the administrator for help ,ip: host1 ,port: 9101 ,serviceKind: linkis-cg-linkismanager ,ip: host1 ,port: 9104 ,serviceKind: linkis-cg-entrance
Exception in thread "main" java.lang.NullPointerException
at com.webank.wedatasphere.linkis.rpc.sender.SpringCloudFeignConfigurationCache$.getClient(SpringCloudFeignConfigurationCache.scala:73)
at com.webank.wedatasphere.linkis.rpc.sender.SpringMVCRPCSender.doBuilder(SpringMVCRPCSender.scala:49)
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=250m; support was removed in 8.0
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
Exception in thread "main" java.lang.NullPointerException
at com.webank.wedatasphere.linkis.rpc.sender.SpringCloudFeignConfigurationCache$.getClient(SpringCloudFeignConfigurationCache.scala:73)
at com.webank.wedatasphere.linkis.rpc.sender.SpringMVCRPCSender.doBuilder(SpringMVCRPCSender.scala:49)
at com.webank.wedatasphere.linkis.rpc.BaseRPCSender.newRPC(BaseRPCSender.scala:67)
at com.webank.wedatasphere.linkis.rpc.BaseRPCSender.com$webank$wedatasphere$linkis$rpc$BaseRPCSender$$getRPC(BaseRPCSender.scala:54)
at com.webank.wedatasphere.linkis.rpc.BaseRPCSender.send(BaseRPCSender.scala:105)
at com.webank.wedatasphere.linkis.engineconn.callback.service.AbstractEngineConnStartUpCallback.callback(EngineConnCallback.scala:39)
at com.webank.wedatasphere.linkis.engineconn.callback.hook.CallbackEngineConnHook.afterEngineServerStartFailed(CallbackEngineConnHook.scala:63)
at com.webank.wedatasphere.linkis.engineconn.launch.EngineConnServer$$anonfun$main$15.apply(EngineConnServer.scala:64)
at com.webank.wedatasphere.linkis.engineconn.launch.EngineConnServer$$anonfun$main$15.apply(EngineConnServer.scala:64)
at scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:186)
at com.webank.wedatasphere.linkis.engineconn.launch.EngineConnServer$.main(EngineConnServer.scala:64)
at com.webank.wedatasphere.linkis.engineconn.launch.EngineConnServer.main(EngineConnServer.scala)
解决方案:/opt/kepler/work/engine/hadoop/workDir/9c28976e-63ba-4d9d-b85e-b37d84144596目录下conf为空导致的。lib和conf是在微服务启动时,由系统检查到(linkis/lib/linkis-engineconn-plugins/python)python引擎物料包zip变化,自动上传至engine/engineConnPublickDir/目录下。临时解决问题是将linkis/lib/linkis-engineconn-plugins/python下的lib和conf内容复制到engine/engineConnPublickDir/对应的目录(即workDir/9c28976e-63ba-4d9d-b85e-b37d84144596里的外链接引用的目录)下。正式方案需解决物料包变化未能成功上传到engineConnPublickDir的问题。
Q24: 安装Exchangis0.5.0后通过dss菜单点击进入新页面提示“Sorry, Page Not Found”。F12查看有404异常
错误信息:F12查看到vue.runtime.esm.js:6785 GET http://10.0.xx.xx:29008/udes/auth?redirect=http%3A%2F%2F10.0.xx.xx%3A29008&dssurl=http%3A%2F%2F10.0.xx.xx%3A8088&cookies=bdp-user-ticket-id%3DM7UZXQP9Ld1xeftV5DUGYeHdOc9oAFgW2HLiVea4FcQ%3D%3B%20workspaceId%3D225 404 (Not Found)
Q25: HIVE 里面配置atlas出现死循环导致堆栈溢出
需要将${ATLAS_HOME}/atlas/hook/hive/ 下所有内容jar包及子目录加入到hive engine 的 lib目录下,不然AtlasPluginClassLoader找不到正确的实现类而找到的是hive-bridge-shim下的类,导致死循环 但是Linkis(1.0.2)现在的执行方式不支持lib下有子目录,需要修改代码,参考: https://github.com/apache/linkis/pull/1058
Q26: Linkis1.0.X基于 spark3 hadoop3 hive3 或 hdp3.1.4 编译需要修改的地方请参考:
https://github.com/lordk911/Linkis/commits/master 编译好之后DSS请依据编译好的包重新编译,scala保持版本一致,web模块用全家桶的就行
Q27 linkis 执行jdbc任务无法获取到用户名
2021-10-31 05:16:54.016 ERROR Task is Failed,errorMsg: NullPointerException: jdbc.username cannot be null. 源代码:com.webank.wedatasphere.linkis.manager.engineplugin.jdbc.executer.JDBCEngineConnExecutor 接收到的val properties = engineExecutorContext.getProperties.asInstanceOf[util.Map[String, String]] 没有jdbc.username 参数
解决方法1: 文档:JDBC问题临时修复方法.note 链接:http://note.youdao.com/noteshare?id=08163f429dd2e226a13877eba8bad1e3&sub=4ADEE86F433B4A59BBB20621A1C4B2AE 解决方法2:对比修改此文件 https://github.com/apache/linkis/blob/319213793881b0329022cf4137ee8d4c502395c7/linkis-engineconn-plugins/engineconn-plugins/jdbc/src/main/scala/com/webank/wedatasphere/linkis/manager/engineplugin/jdbc/executer/JDBCEngineConnExecutor.scala
Q28: 安装前更改配置中的hive版本后,管理台的配置中仍然显示版本为2.3.3
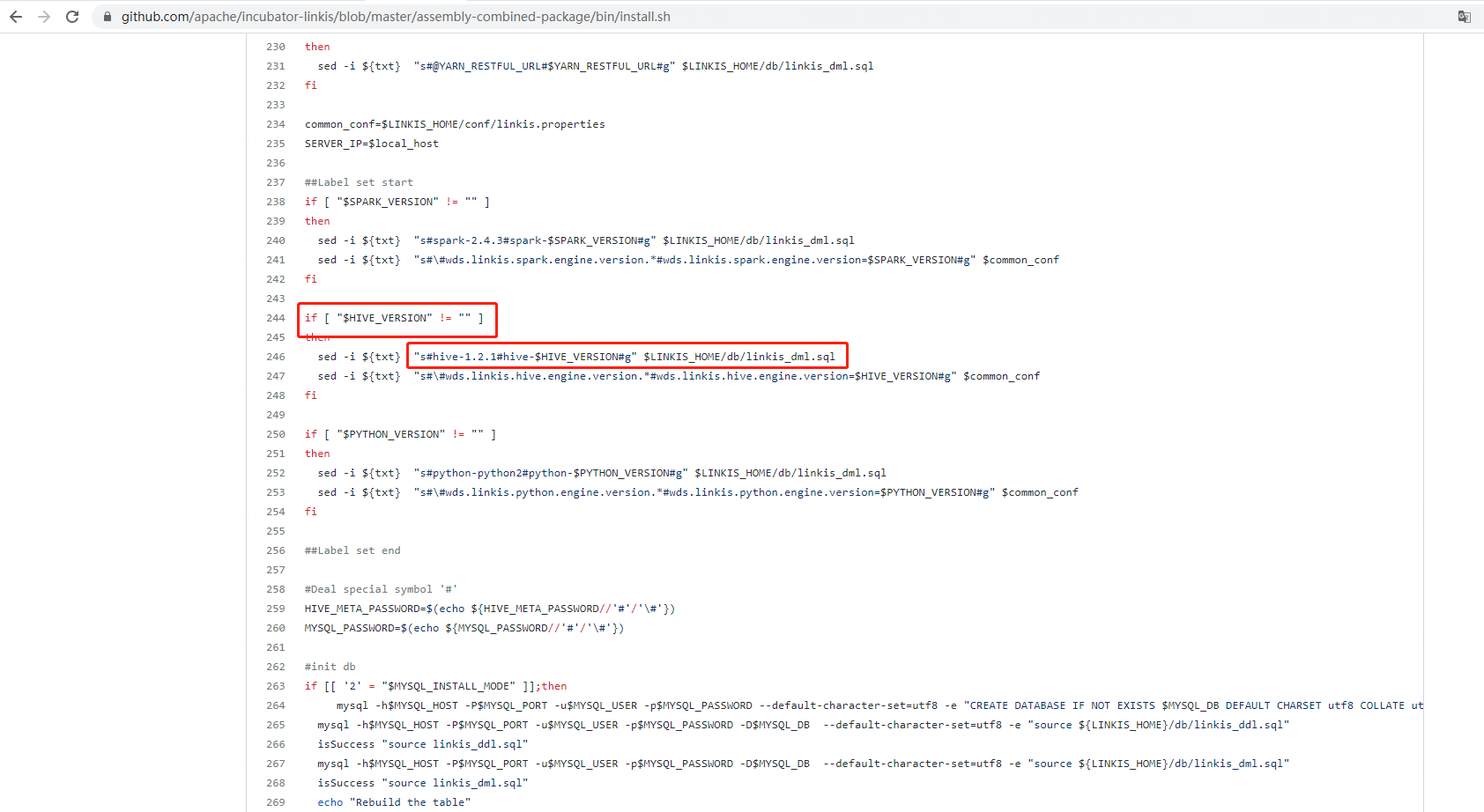
方案一:确定为安装install.sh脚本存在bug,请将此处的hive-1.2.1改成hive-2.3.3后重新安装即可。 方案二:如果不想重新安装,则需要在linkis_cg_manager_label表中label_value包含hive-2.3.3的所有值改成希望的hive版本即可 Note:欢迎将此问题在github Linkis项目提交PR进行修复,然后告知我们,我们会尽快review并合并到代码中(目前未修复,Deadline 2021年11月30日)
Q29: linkis-cli 提交任务,提示GROUP BY clause; sql_mode=only_full_group_by错误
_8_codeExec_8 com.webank.wedatasphere.linkis.orchestrator.ecm.exception.ECMPluginErrorException: errCode: 12003 ,desc: uathadoop01:9101_8 Failed to async get EngineNode MySQLSyntaxErrorException: Expression #6 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'dss_linkis.si.name' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by ,ip: uathadoop01 ,port: 9104 ,serviceKind: linkis-cg-entrance
原因:这个错误发生在mysql 5.7 版本及以上版本会出现的问题:因为配置严格执行了"SQL92标准",解决方法:进入/etc/mysql目录下修改my.cnf文件 在 [mysqld] 下面添加代码: sql_mode = STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
Q30: flink引擎启动时报错找到TokenCache
ERROR [main] com.webank.wedatasphere.linkis.engineconn.computation.executor.hook.ComputationEngineConnHook 57 error - EngineConnSever start failed! now exit. java.lang.NoClassDefFoundError: org/apache/hadoop/mapreduce/security/TokenCache 原因:flink-enginecon lib下缺少hadoop-mapreduce-client-core.jar这个jar包,从hadoop的lib下拷贝一份即可。
Q31: 启动flink引擎/spark引擎时,engine-entrance报错org.json4s.JsonAST$JNothing$ cannot be cast to org.json4s.JsonAST$JString
原因是linkis-manager里面报错yarn队列获取异常 解决办法:修改linkis_cg_rm_external_resource_provider表中修改对应config的yarn队列信息
Q32:函数脚本执行时报ClassNotFoundException

原因:linkis创建函数的方式是通过把函数所在的路径加入到classPath下,再执行create temporary function。。。语句,此种方式往yarn集群上提交任务时并不会把函数的jar包上传到hdfs上,造成类加载失败!
解决办法:修改生成函数语句的方法,或者利用HiveAddJarsEngineHook解决,这里修改JarUdfEngineHook的constructCode方法。打包后替换所有的
override protected def constructCode(udfInfo: UDFInfo): String = {
"%sql\n" + "add jar " + udfInfo.getPath + "\n%sql\n" + udfInfo.getRegisterFormat
}
Q33: CDH环境Linkis执行Spark任务报:Failed to start bean 'webServerStartStop
详细日志:
Caused by: java.lang.IllegalStateException
at org.eclipse.jetty.servlet.ServletHolder.setClassFrom(ServletHolder.java:300) ~[jetty-servlet-9.4.48.v20220622.jar:9.4.48.v20220622]
at org.eclipse.jetty.servlet.ServletHolder.doStart(ServletHolder.java:347) ~[jetty-servlet-9.4.48.v20220622.jar:9.4.48.v20220622]
at org.eclipse.jetty.util.component.AbstractLifeCycle.start(AbstractLifeCycle.java:73) ~[jetty-util-9.4.48.v20220622.jar:9.4.48.v20220622]
at org.eclipse.jetty.servlet.ServletHandler.lambda$initialize$0(ServletHandler.java:749) ~[jetty-servlet-9.4.48.v20220622.jar:9.4.48.v20220622]
at java.util.stream.SortedOps$SizedRefSortingSink.end(SortedOps.java:357) ~[?:1.8.0_292]
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:483) ~[?:1.8.0_292]
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:472) ~[?:1.8.0_292]
at java.util.stream.StreamSpliterators$WrappingSpliterator.forEachRemaining(StreamSpliterators.java:313) ~[?:1.8.0_292]
at java.util.stream.Streams$ConcatSpliterator.forEachRemaining(Streams.java:743) ~[?:1.8.0_292]
at java.util.stream.ReferencePipeline$Head.forEach(ReferencePipeline.java:647) ~[?:1.8.0_292]
at org.eclipse.jetty.servlet.ServletHandler.initialize(ServletHandler.java:774) ~[jetty-servlet-9.4.48.v20220622.jar:9.4.48.v20220622]
at org.springframework.boot.web.embedded.jetty.JettyEmbeddedWebAppContext$JettyEmbeddedServletHandler.deferredInitialize(JettyEmbeddedWebAppContext.java:46) ~[spring-boot-2.3.12.RELEASE.jar:2.3.12.RELEASE]
at
原因:这个是因为CDH—Spark底层依赖的classPath和Linkis的存在冲突导致 解决办法:在linkis部署的机器上面可以检查spark-env.sh里面的classPath并进行注释掉,重新运行。详情可以参考3282
Q34: 运行flink任务时报错:Failed to create engineConnPlugin: com.webank.wedatasphere.linkis.engineplugin.hive.HiveEngineConnPluginjava.lang.ClassNotFoundException: com.webank.wedatasphere.linkis.engineplugin.hive.HiveEngineConnPlugin

原因:flink引擎目录下的conf里的配置文件为空,读取了默认的配置(默认读取hived引擎的配置),删除配置表中关于flink的conf 然后重启ecp