Hive Engine
This article mainly introduces the configuration, deployment and use of Hive engineConn in Linkis1.0.
1. Environment configuration before Hive engineConn use
If you want to use the hive engineConn on your linkis server, you need to ensure that the following environment variables have been set correctly and that the user who started the engineConn has these environment variables.
It is strongly recommended that you check these environment variables of the executing user before executing hive tasks.
| Environment variable name | Environment variable content | Remarks |
|---|---|---|
| JAVA_HOME | JDK installation path | Required |
| HADOOP_HOME | Hadoop installation path | Required |
| HADOOP_CONF_DIR | Hadoop configuration path | Required |
| HIVE_CONF_DIR | Hive configuration path | Required |
Table 1-1 Environmental configuration list
2. Hive engineConn configuration and deployment
2.1 Hive version selection and compilation
The version of Hive supports hive1.x/hive2.x/hive3.x. The hive version supported by default is 2.3.3. If you want to modify the hive version, such as 2.3.3, you can find the linkis-engineConnplugin-hive module and change the \<hive.version> tag to 2.3 .3, then compile this module separately.
The default is to support hive on MapReduce, if you want to change to Hive on Tez, You need to copy all the jars prefixed with tez-* to the directory: ${LINKIS_HOME}/lib/linkis-engineconn-plugins/hive/dist/version/lib.
Other hive operating modes are similar, just copy the corresponding dependencies to the lib directory of Hive EngineConn.
2.2 hive engineConnConn deployment and loading
If you have already compiled your hive engineConn plug-in has been compiled, then you need to put the new plug-in in the specified location to load, you can refer to the following article for details
2.3 Linkis adds Hive console parameters(optional)
Linkis can configure the corresponding EngineConn parameters on the management console. If your newly added EngineConn needs this feature, you can refer to the following documents:
EngineConnPlugin Installation > 2.2 Configuration modification of management console (optional)
3. Use of hive engineConn
Preparation for operation, queue setting
Hive's MapReduce task requires yarn resources, so you need to set up the queue at the beginning
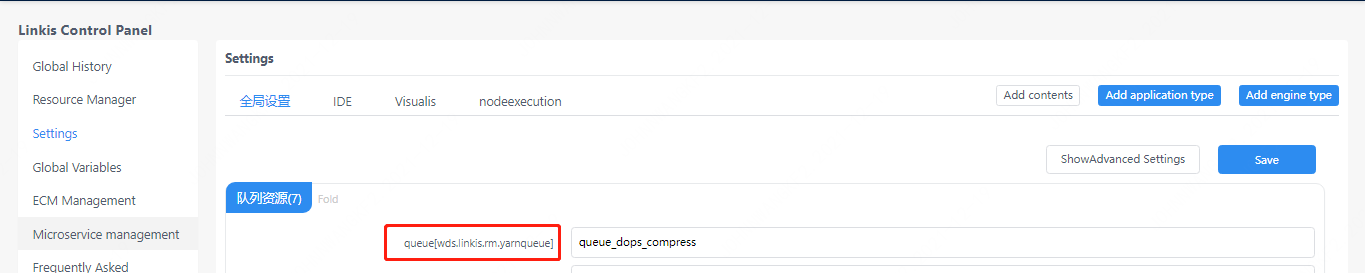
Figure 3-1 Queue settings
You can also add the queue value in the StartUpMap of the submission parameter: startupMap.put("wds.linkis.rm.yarnqueue", "dws")
3.1 How to use Linkis SDK
Linkis provides a client method to call hive tasks. The call method is through the SDK provided by LinkisClient. We provide java and scala two ways to call, the specific usage can refer to JAVA SDK Manual. If you use Hive, you only need to make the following changes:
Map<String, Object> labels = new HashMap<String, Object>();
labels.put(LabelKeyConstant.ENGINE_TYPE_KEY, "hive-2.3.3"); // required engineType Label
labels.put(LabelKeyConstant.USER_CREATOR_TYPE_KEY, "hadoop-IDE");// required execute user and creator
labels.put(LabelKeyConstant.CODE_TYPE_KEY, "hql"); // required codeType
3.2 How to use Linkis-cli
After Linkis 1.0, you can submit tasks through cli. We only need to specify the corresponding EngineConn and CodeType tag types. The use of Hive is as follows:
sh ./bin/linkis-cli -engineType jdbc-4 -codeType jdbc -code "show tables" -submitUser hadoop -proxyUser hadoop
The specific usage can refer to Linkis CLI Manual.
3.3 How to use Scriptis
The use of Scriptis is the simplest. You can directly enter Scriptis, right-click the directory and create a new hive script and write hivesql code.
The implementation of the hive engineConn is by instantiating the driver instance of hive, and then the driver submits the task, and obtains the result set and displays it.
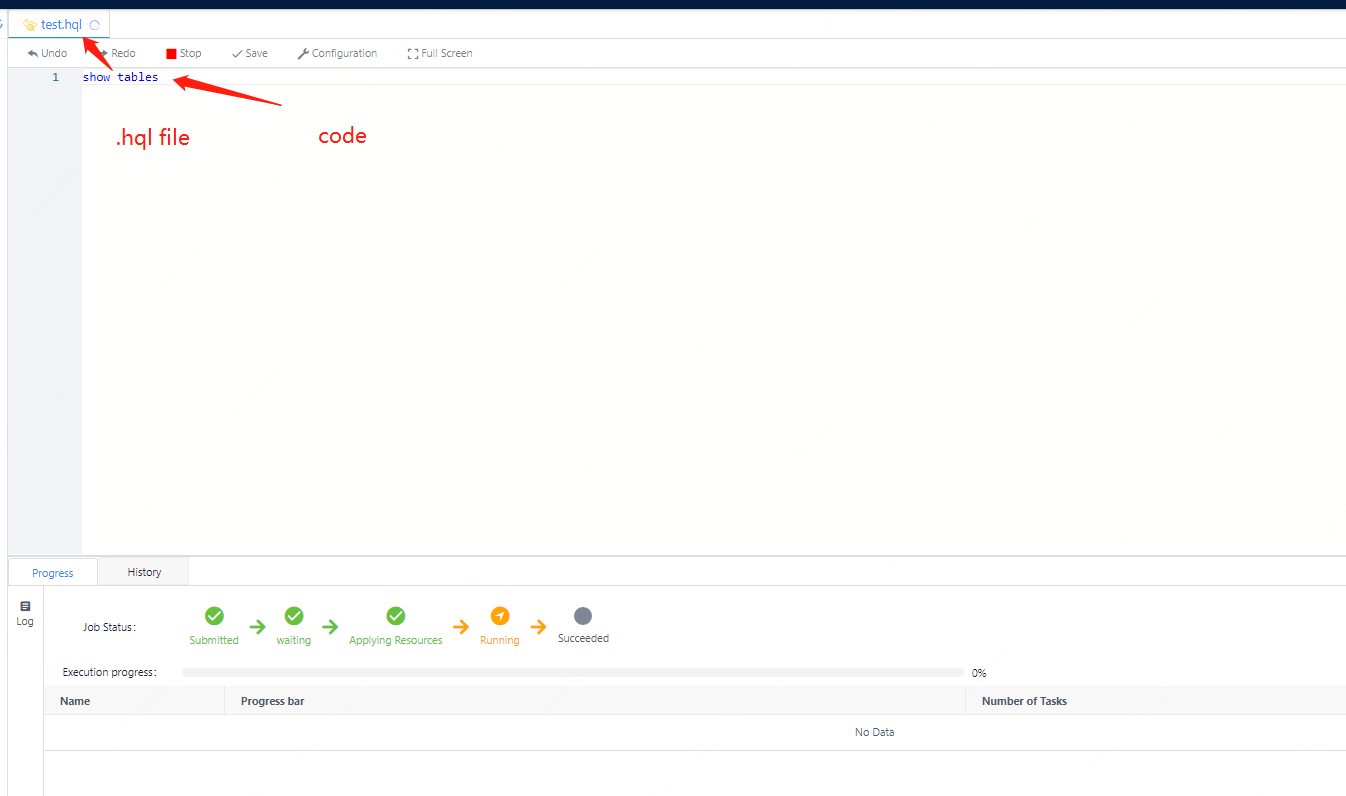
Figure 3-2 Screenshot of the execution effect of hql
4. Hive engineConn user settings
In addition to the above engineConn configuration, users can also make custom settings, including the memory size of the hive Driver process, etc.
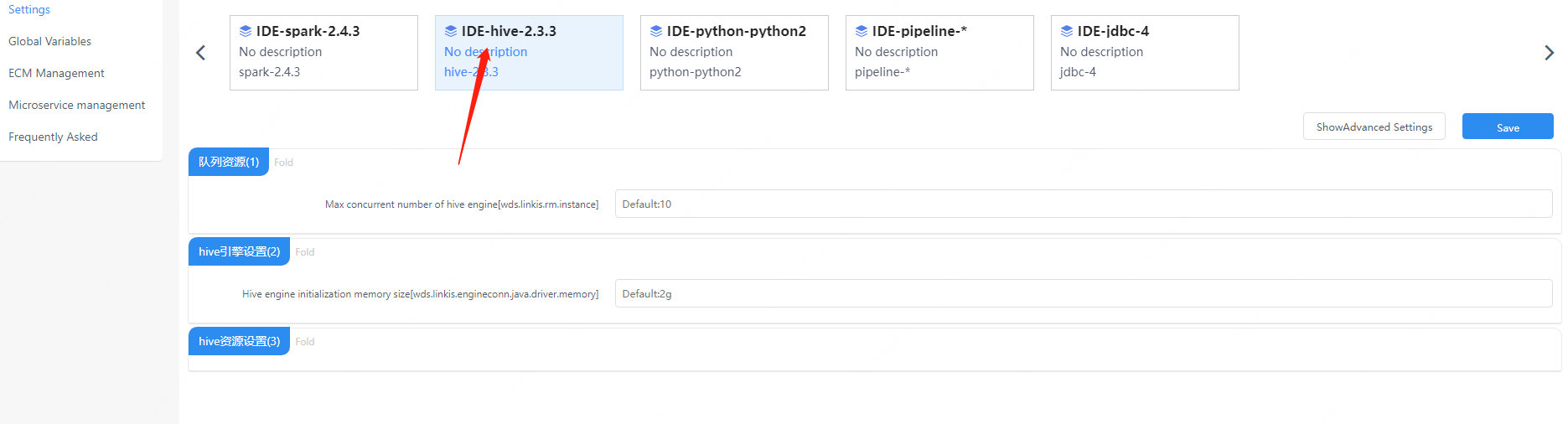
Figure 4-1 User-defined configuration management console of hive
5.Hive modification log display
The default log interface does not display the application_id and the number of tasks completed, the user can output the log as needed The code blocks that need to be modified in the log4j2-engineconn.xml/log4j2.xml configuration file in the engine are as follows 1.Need to add under the appenders component
<Send name="SendPackage" >
<PatternLayout pattern="%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level [%t] %logger{36} %L %M - %msg%xEx%n"/>
</Send>
2.Need to add under the root component
<appender-ref ref="SendPackage"/>
3.Need to add under the loggers component
<logger name="org.apache.hadoop.hive.ql.exec.StatsTask" level="info" additivity="true">
<appender-ref ref="SendPackage"/>
</logger>
After making the above relevant modifications, the log can add task progress information, which is displayed in the following style
2022-04-08 11:06:50.228 INFO [Linkis-Default-Scheduler-Thread-3] SessionState 1111 printInfo - Status: Running (Executing on YARN cluster with App id application_1631114297082_432445)
2022-04-08 11:06:50.248 INFO [Linkis-Default-Scheduler-Thread-3] SessionState 1111 printInfo - Map 1: -/- Reducer 2: 0/1
2022-04-08 11:06:52.417 INFO [Linkis-Default-Scheduler-Thread-3] SessionState 1111 printInfo - Map 1: 0/1 Reducer 2: 0/1
2022-04-08 11:06:55.060 INFO [Linkis-Default-Scheduler-Thread-3] SessionState 1111 printInfo - Map 1: 0(+1)/1 Reducer 2: 0/1
2022-04-08 11:06:57.495 INFO [Linkis-Default-Scheduler-Thread-3] SessionState 1111 printInfo - Map 1: 1/1 Reducer 2: 0(+1)/1
2022-04-08 11:06:57.899 INFO [Linkis-Default-Scheduler-Thread-3] SessionState 1111 printInfo - Map 1: 1/1 Reducer 2: 1/1
An example of a complete xml configuration file is as follows:
<!--
~ Copyright 2019 WeBank
~
~ Licensed under the Apache License, Version 2.0 (the "License");
~ you may not use this file except in compliance with the License.
~ You may obtain a copy of the License at
~
~ http://www.apache.org/licenses/LICENSE-2.0
~
~ Unless required by applicable law or agreed to in writing, software
~ distributed under the License is distributed on an "AS IS" BASIS,
~ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
~ See the License for the specific language governing permissions and
~ limitations under the License.
-->
<configuration status="error" monitorInterval="30">
<appenders>
<Console name="Console" target="SYSTEM_OUT">
<ThresholdFilter level="INFO" onMatch="ACCEPT" onMismatch="DENY"/>
<PatternLayout pattern="%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level [%t] %logger{36} %L %M - %msg%xEx%n"/>
</Console>
<Send name="Send" >
<Filters>
<ThresholdFilter level="WARN" onMatch="ACCEPT" onMismatch="DENY" />
</Filters>
<PatternLayout pattern="%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level [%t] %logger{36} %L %M - %msg%xEx%n"/>
</Send>
<Send name="SendPackage" >
<PatternLayout pattern="%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level [%t] %logger{36} %L %M - %msg%xEx%n"/>
</Send>
<Console name="stderr" target="SYSTEM_ERR">
<ThresholdFilter level="ERROR" onMatch="ACCEPT" onMismatch="DENY" />
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level %class{36} %L %M - %msg%xEx%n"/>
</Console>
</appenders>
<loggers>
<root level="INFO">
<appender-ref ref="stderr"/>
<appender-ref ref="Console"/>
<appender-ref ref="Send"/>
<appender-ref ref="SendPackage"/>
</root>
<logger name="org.apache.hadoop.hive.ql.exec.StatsTask" level="info" additivity="true">
<appender-ref ref="SendPackage"/>
</logger>
<logger name="org.springframework.boot.diagnostics.LoggingFailureAnalysisReporter" level="error" additivity="true">
<appender-ref ref="stderr"/>
</logger>
<logger name="com.netflix.discovery" level="warn" additivity="true">
<appender-ref ref="Send"/>
</logger>
<logger name="org.apache.hadoop.yarn" level="warn" additivity="true">
<appender-ref ref="Send"/>
</logger>
<logger name="org.springframework" level="warn" additivity="true">
<appender-ref ref="Send"/>
</logger>
<logger name="org.apache.linkis.server.security" level="warn" additivity="true">
<appender-ref ref="Send"/>
</logger>
<logger name="org.apache.hadoop.hive.ql.exec.mr.ExecDriver" level="fatal" additivity="true">
<appender-ref ref="Send"/>
</logger>
<logger name="org.apache.hadoop.hdfs.KeyProviderCache" level="fatal" additivity="true">
<appender-ref ref="Send"/>
</logger>
<logger name="org.spark_project.jetty" level="ERROR" additivity="true">
<appender-ref ref="Send"/>
</logger>
<logger name="org.eclipse.jetty" level="ERROR" additivity="true">
<appender-ref ref="Send"/>
</logger>
<logger name="org.springframework" level="ERROR" additivity="true">
<appender-ref ref="Send"/>
</logger>
<logger name="org.reflections.Reflections" level="ERROR" additivity="true">
<appender-ref ref="Send"/>
</logger>
<logger name="org.apache.hadoop.ipc.Client" level="ERROR" additivity="true">
<appender-ref ref="Send"/>
</logger>
</loggers>
</configuration>