JDBC Engine
This article mainly introduces the configuration, deployment and use of JDBC EngineConn in Linkis1.0.
1. Environment configuration before using the JDBC EngineConn
If you want to use the JDBC EngineConn on your server, you need to prepare the JDBC connection information, such as the connection address, user name and password of the MySQL database, etc.
2. JDBC EngineConn configuration and deployment
2.1 JDBC version selection and compilation
The JDBC EngineConn does not need to be compiled by the user, and the compiled JDBC EngineConn plug-in package can be used directly. Drivers that have been provided include MySQL, PostgreSQL, etc.
2.2 JDBC EngineConn deployment and loading
Here you can use the default loading method to use it normally, just install it according to the standard version.
2.3 JDBC EngineConn Labels
Here you can use the default dml.sql to insert it and it can be used normally.
3. The use of JDBC EngineConn
Ready to operate
You need to configure JDBC connection information, including connection address information and user name and password.
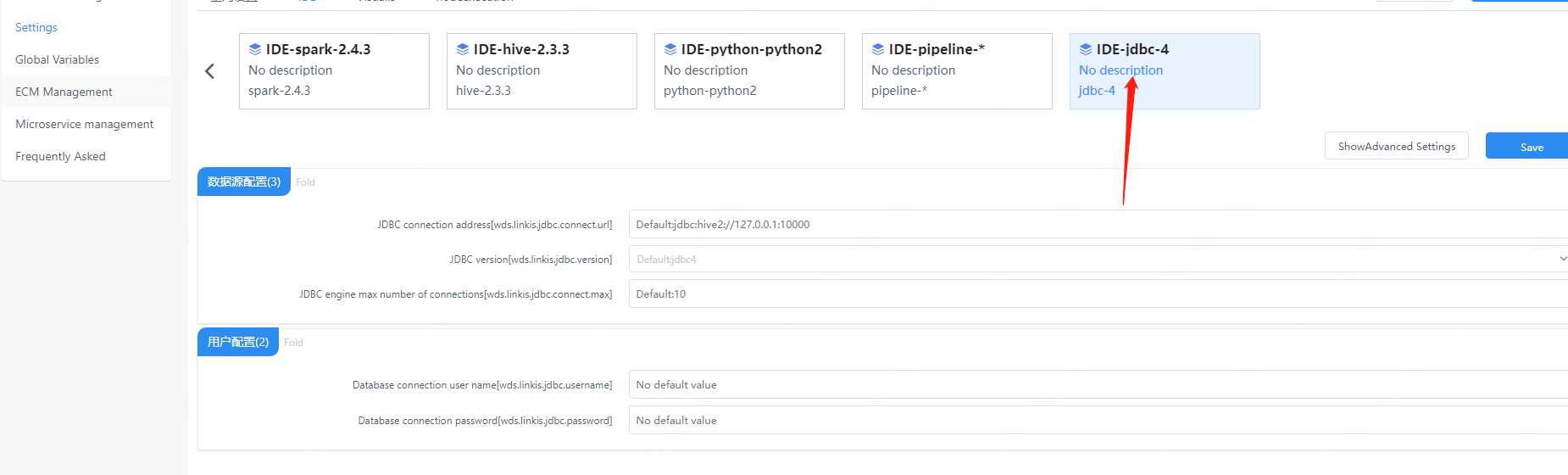
Figure 3-1 JDBC configuration information
You can also specify in the RuntimeMap of the submitted task
wds.linkis.jdbc.connect.url
wds.linkis.jdbc.driver
wds.linkis.jdbc.username
wds.linkis.jdbc.password
You can also set parameters on the task submission interface.
http request params example
{
"executionContent": {"code": "show databases;", "runType": "jdbc"},
"params": {
"variable": {},
"configuration": {
"runtime": {
"wds.linkis.jdbc.connect.url":"jdbc:mysql://127.0.0.1:3306/test",
"wds.linkis.jdbc.driver":"com.mysql.jdbc.Driver",
"wds.linkis.jdbc.username":"test",
"wds.linkis.jdbc.password":"test23"
}
}
},
"source": {"scriptPath": "file:///mnt/bdp/hadoop/1.sql"},
"labels": {
"engineType": "jdbc-4",
"userCreator": "hadoop-IDE"
}
}
3.1 How to use Linkis SDK
Linkis provides a client method to call jdbc tasks. The call method is through the SDK provided by LinkisClient. We provide java and scala two ways to call, the specific usage can refer to JAVA SDK Manual. If you use Hive, you only need to make the following changes:
Map<String, Object> labels = new HashMap<String, Object>();
labels.put(LabelKeyConstant.ENGINE_TYPE_KEY, "jdbc-4"); // required engineType Label
labels.put(LabelKeyConstant.USER_CREATOR_TYPE_KEY, "hadoop-IDE");// required execute user and creator
labels.put(LabelKeyConstant.CODE_TYPE_KEY, "jdbc"); // required codeType
3.2 How to use Linkis-cli
After Linkis 1.0, you can submit tasks through cli. We only need to specify the corresponding EngineConn and CodeType tag types. The use of JDBC is as follows:
sh ./bin/linkis-cli -engineType jdbc-4 -codeType jdbc -code "show tables" -submitUser hadoop -proxyUser hadoop
The specific usage can refer to Linkis CLI Manual.
3.3 How to use Scriptis
The way to use Scriptis is the simplest. You can go directly to Scriptis, right-click the directory and create a new JDBC script, write JDBC code and click Execute.
The execution principle of JDBC is to load the JDBC Driver and submit sql to the SQL server for execution and obtain the result set and return.
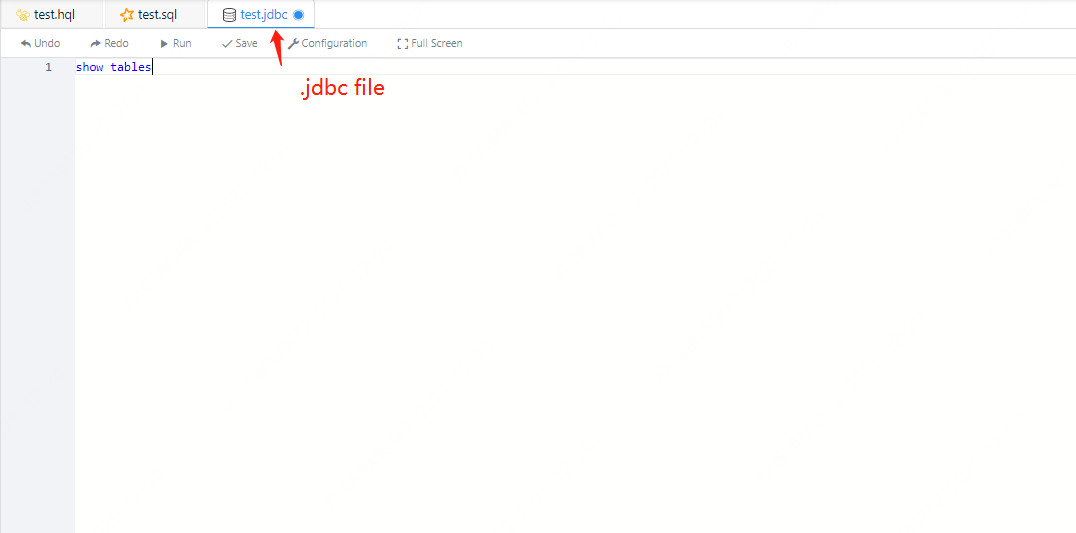
Figure 3-2 Screenshot of the execution effect of JDBC
3.4 DataSource Manage
Linkis provides data source management function after 1.2.0, we can manage different data sources in the console. Address: Login management desktop --> DataSource Manage --> Add Source
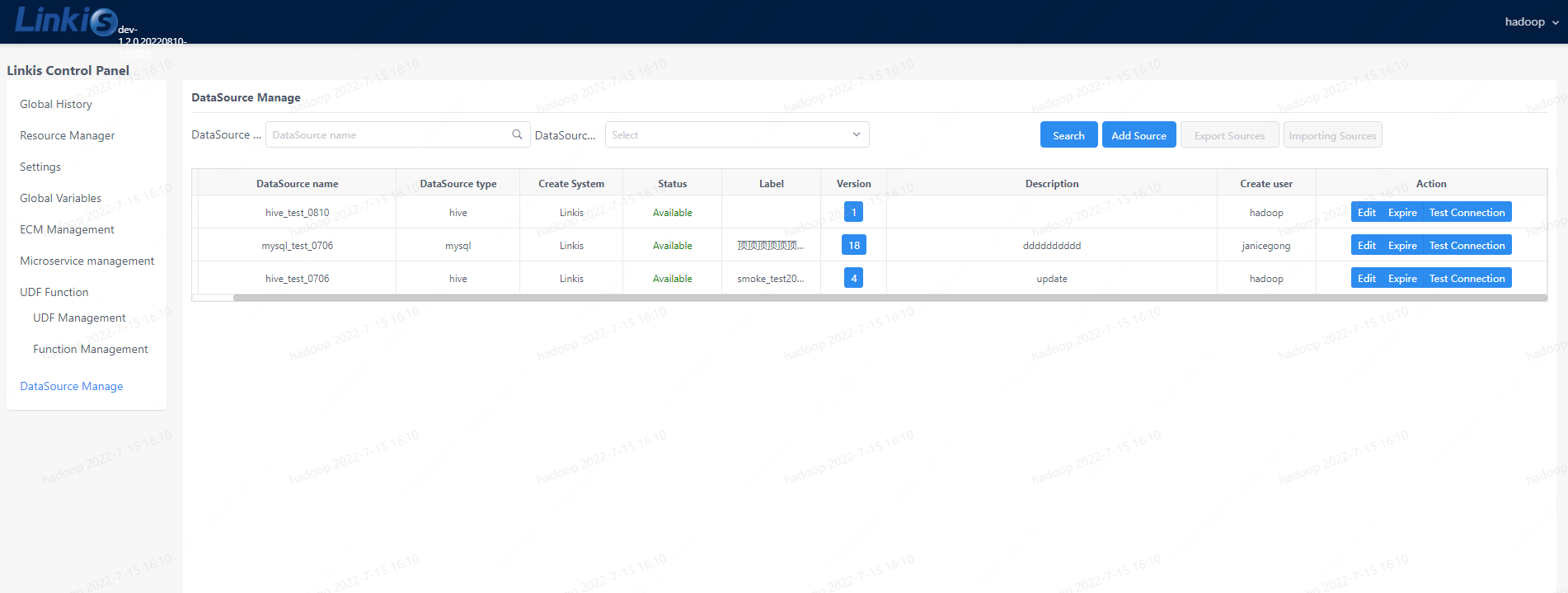
Figure 3-3 DataSource Manage
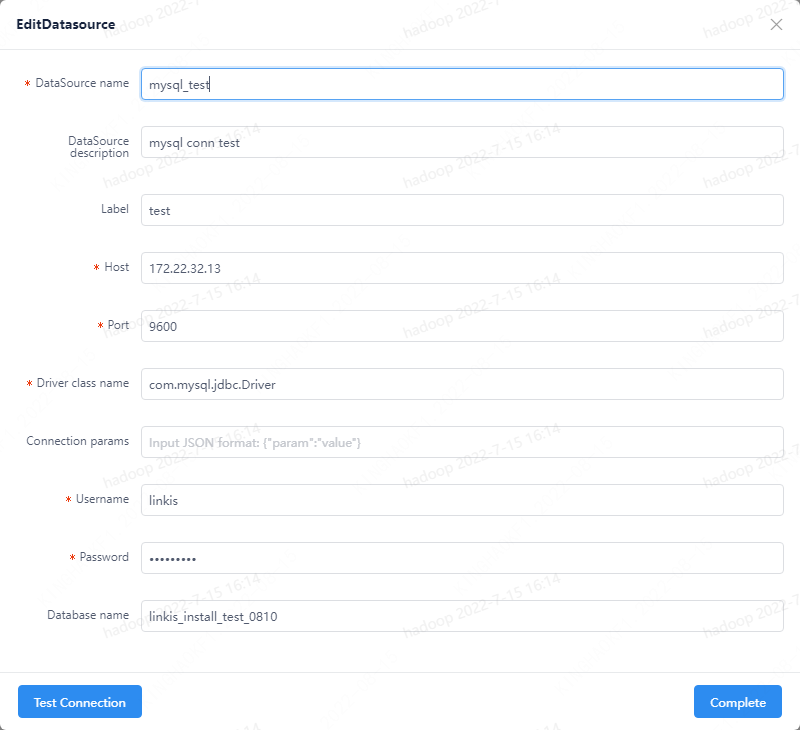
Figure 3-4 DataSource Conn Test
After the data source is completed, you can use the JDBC multi-data source switch to add, there are functional methods:
- Specify the data source name parameter through the interface parameter Example parameters:
{
"executionContent": {
"code": "show databases",
"runType": "jdbc"
},
"params": {
"variable": {},
"configuration": {
"startup": {},
"runtime": {
"wds.linkis.engine.runtime.datasource": "test_mysql"
}
}
},
"source": {
"scriptPath": ""
},
"labels": {
"engineType": "jdbc-4",
"userCreator": "hadoop-IDE"
}
}
Parameter: wds.linkis.engine.runtime.datasource is a configuration with a fixed name, do not modify the name definition arbitrarily
- Through the Scripts code submission entry of DSS, drop down and filter the data sources to be submitted, as shown in the following figure:
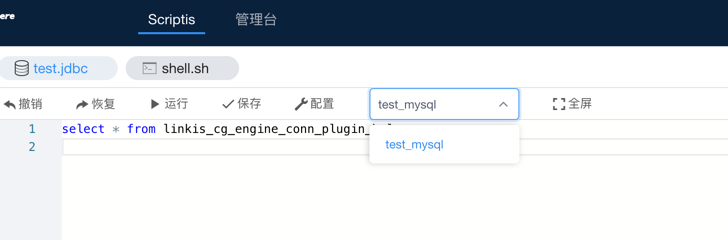
Currently dss-1.1.0 does not yet support drop-down selection of data source name, PR is under development, you can wait for subsequent releases or pay attention to related PRs: (https://github.com/WeBankFinTech/DataSphereStudio/issues/940)
Function description of multiple data sources:
1) In the previous version, the JDBC engine's support for data sources was not perfect, especially when used with Scripts, the jdbc script type can only bind a set of JDBC engine parameters of the console. When we need to switch multiple data sources, we can only modify the connection parameters of the jdbc engine, which is troublesome.
2) With the data source management, we introduce the multi-data source switching function of the JDBC engine, which can realize that only by setting the data source name, the job can be submitted to different JDBC services, and ordinary users do not need to It maintains the connection information of the data source, avoids the complicated configuration, and also meets the security requirements of the data source connection password and other configurations.
3) The data source set in the multi-data source management can be loaded by the JDBC engine only after it is published, and the data source that has not expired, otherwise, different types of exception prompts will be fed back to the user.
4) The loading priority of jdbc engine parameters is: task submission parameters > select data source parameters > console JDBC engine parameters
4. JDBC EngineConn user settings
JDBC user settings are mainly JDBC connection information, but it is recommended that users encrypt and manage this password and other information.