Spark Engine
This article mainly introduces the configuration, deployment and use of spark EngineConn in Linkis1.0.
1. Environment configuration before using Spark EngineConn
If you want to use the spark EngineConn on your server, you need to ensure that the following environment variables have been set correctly and that the user who started the EngineConn has these environment variables.
It is strongly recommended that you check these environment variables of the executing user before executing spark tasks.
| Environment variable name | Environment variable content | Remarks |
|---|---|---|
| JAVA_HOME | JDK installation path | Required |
| HADOOP_HOME | Hadoop installation path | Required |
| HADOOP_CONF_DIR | Hadoop configuration path | Required |
| HIVE_CONF_DIR | Hive configuration path | Required |
| SPARK_HOME | Spark installation path | Required |
| SPARK_CONF_DIR | Spark configuration path | Required |
| python | python | Anaconda's python is recommended as the default python |
Table 1-1 Environmental configuration list
2. Configuration and deployment of Spark EngineConn
2.1 Selection and compilation of spark version
In theory, Linkis1.0 supports all versions of spark2.x and above. Spark 2.4.3 is the default supported version. If you want to use your spark version, such as spark2.1.0, you only need to modify the version of the plug-in spark and then compile it. Specifically, you can find the linkis-engineplugin-spark module, change the \<spark.version> tag to 2.1.0, and then compile this module separately.
2.2 spark engineConn deployment and loading
If you have already compiled your spark EngineConn plug-in has been compiled, then you need to put the new plug-in to the specified location to load, you can refer to the following article for details
2.3 tags of spark EngineConn
Linkis1.0 is done through tags, so we need to insert data in our database, the way of inserting is shown below.
EngineConnPlugin Installation > 2.2 Configuration modification of management console (optional)
3. Use of spark EngineConn
Preparation for operation, queue setting
Because the execution of spark is a resource that requires a queue, the user must set up a queue that he can execute before executing.
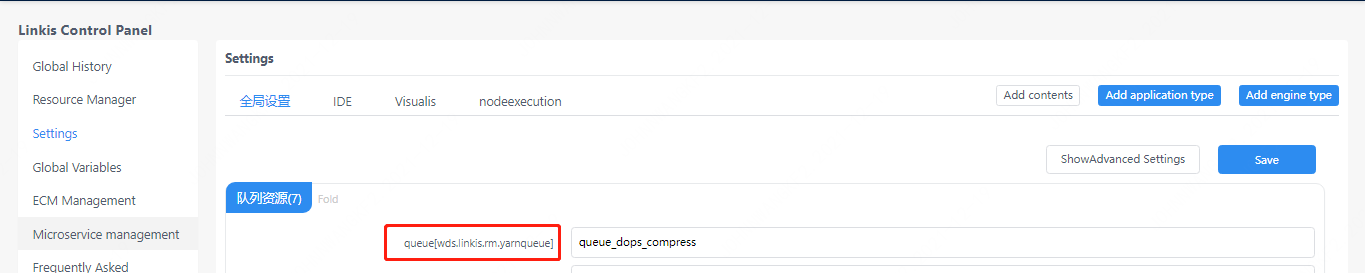
Figure 3-1 Queue settings
You can also add the queue value in the StartUpMap of the submission parameter: startupMap.put("wds.linkis.rm.yarnqueue", "dws")
3.1 How to use Linkis SDK
Linkis provides a client method to call Spark tasks. The call method is through the SDK provided by LinkisClient. We provide java and scala two ways to call, the specific usage can refer to JAVA SDK Manual. If you use Hive, you only need to make the following changes:
Map<String, Object> labels = new HashMap<String, Object>();
labels.put(LabelKeyConstant.ENGINE_TYPE_KEY, "spark-2.4.3"); // required engineType Label
labels.put(LabelKeyConstant.USER_CREATOR_TYPE_KEY, "hadoop-IDE");// required execute user and creator
labels.put(LabelKeyConstant.CODE_TYPE_KEY, "sql"); // required codeType
3.2 How to use Linkis-cli
After Linkis 1.0, you can submit tasks through cli. We only need to specify the corresponding EngineConn and CodeType tag types. The use of Spark is as follows:
## codeType correspondence py-->pyspark sql-->sparkSQL scala-->Spark scala
sh ./bin/linkis-cli -engineType spark-2.4.3 -codeType sql -code "show tables" -submitUser hadoop -proxyUser hadoop
# You can specify the yarn queue in the submission parameter by -confMap wds.linkis.yarnqueue=dws
sh ./bin/linkis-cli -engineType spark-2.4.3 -codeType sql -confMap wds.linkis.yarnqueue=dws -code "show tables" -submitUser hadoop -proxyUser hadoop
The specific usage can refer to Linkis CLI Manual.
3.3 How to use Scriptis
The use of Scriptis is the simplest. You can directly enter Scriptis and create a new sql, scala or pyspark script for execution.
The sql method is the simplest. You can create a new sql script and write and execute it. When it is executed, the progress will be displayed. If the user does not have a spark EngineConn at the beginning, the execution of sql will start a spark session (it may take some time here), After the SparkSession is initialized, you can start to execute sql.
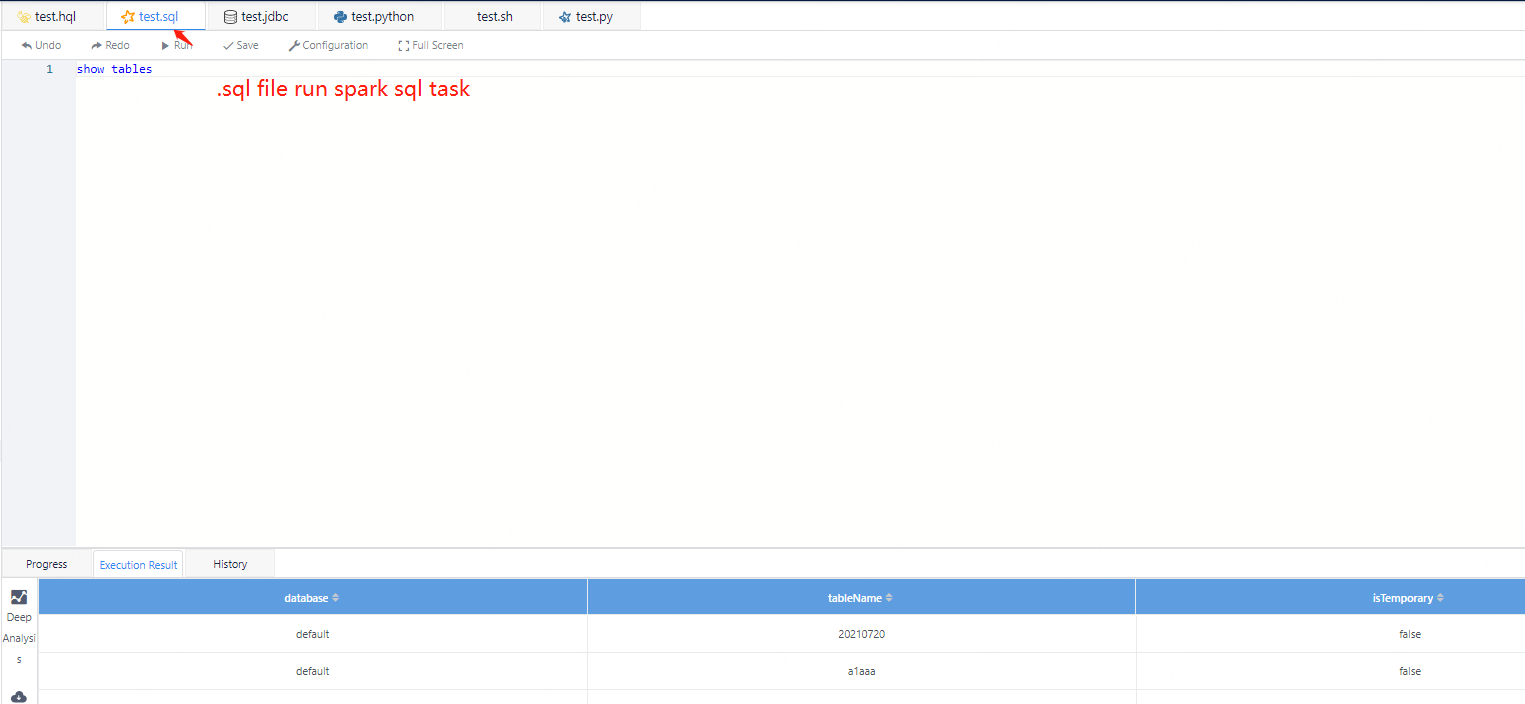
Figure 3-2 Screenshot of the execution effect of sparksql
For spark-scala tasks, we have initialized sqlContext and other variables, and users can directly use this sqlContext to execute sql.
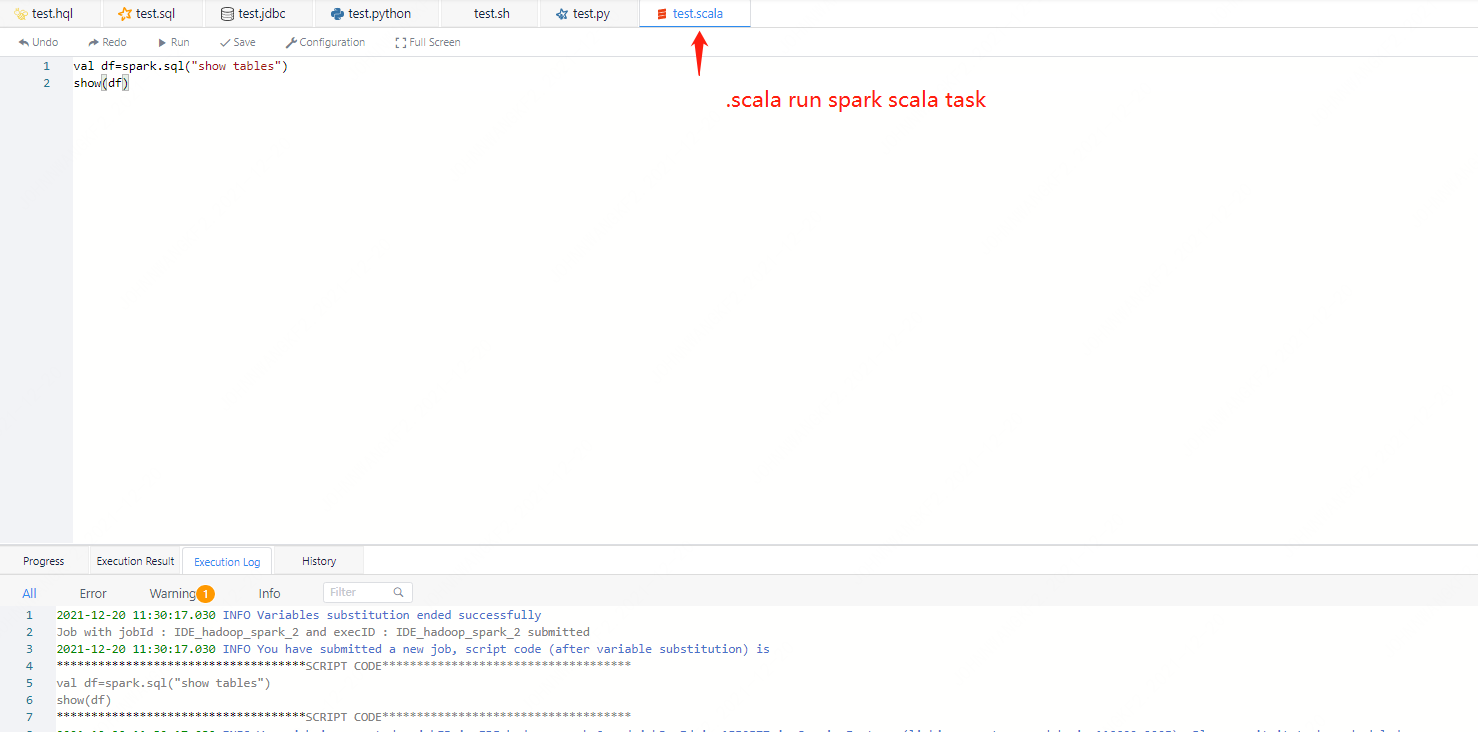
Figure 3-3 Execution effect diagram of spark-scala
Similarly, in the way of pyspark, we have also initialized the SparkSession, and users can directly use spark.sql to execute SQL.
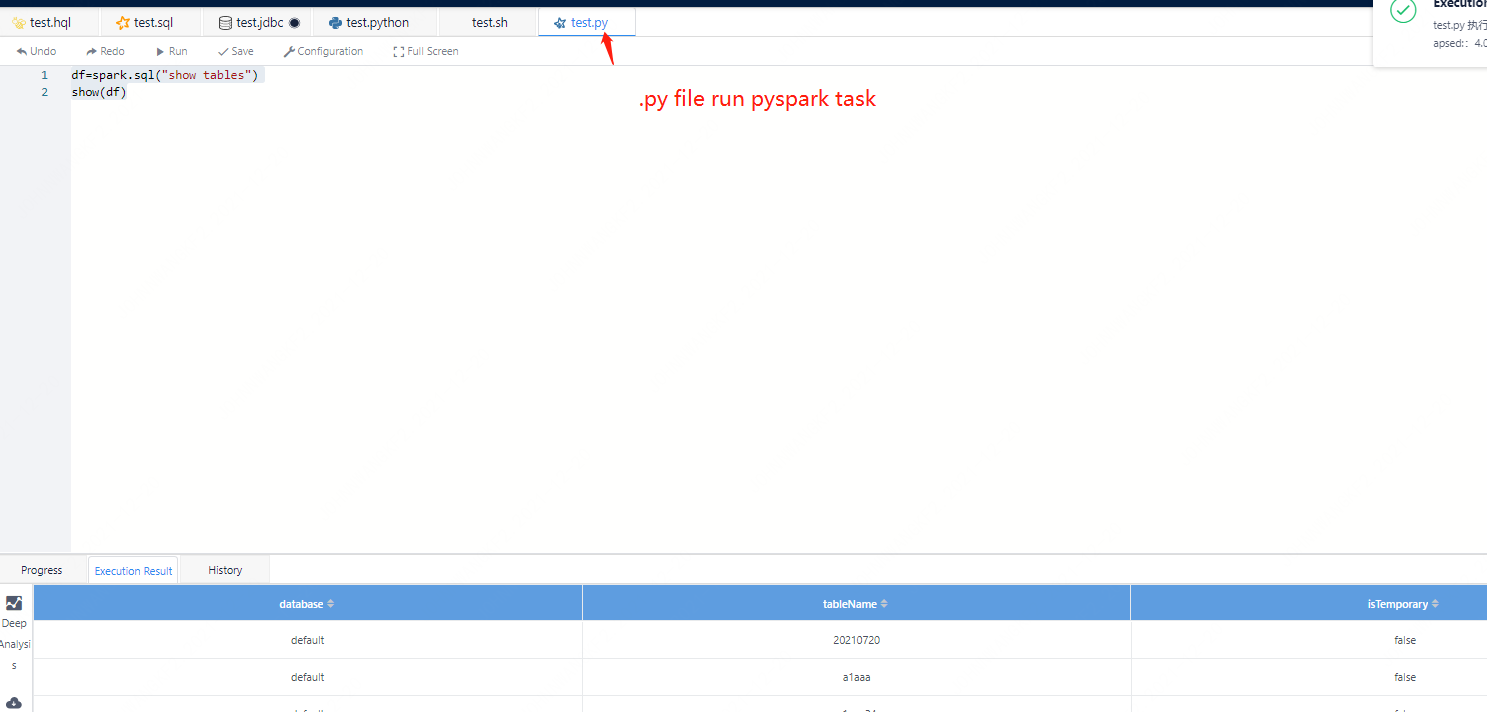 Figure 3-4 pyspark execution mode
Figure 3-4 pyspark execution mode
4. Spark EngineConn user settings
In addition to the above EngineConn configuration, users can also make custom settings, such as the number of spark session executors and the memory of the executors. These parameters are for users to set their own spark parameters more freely, and other spark parameters can also be modified, such as the python version of pyspark.
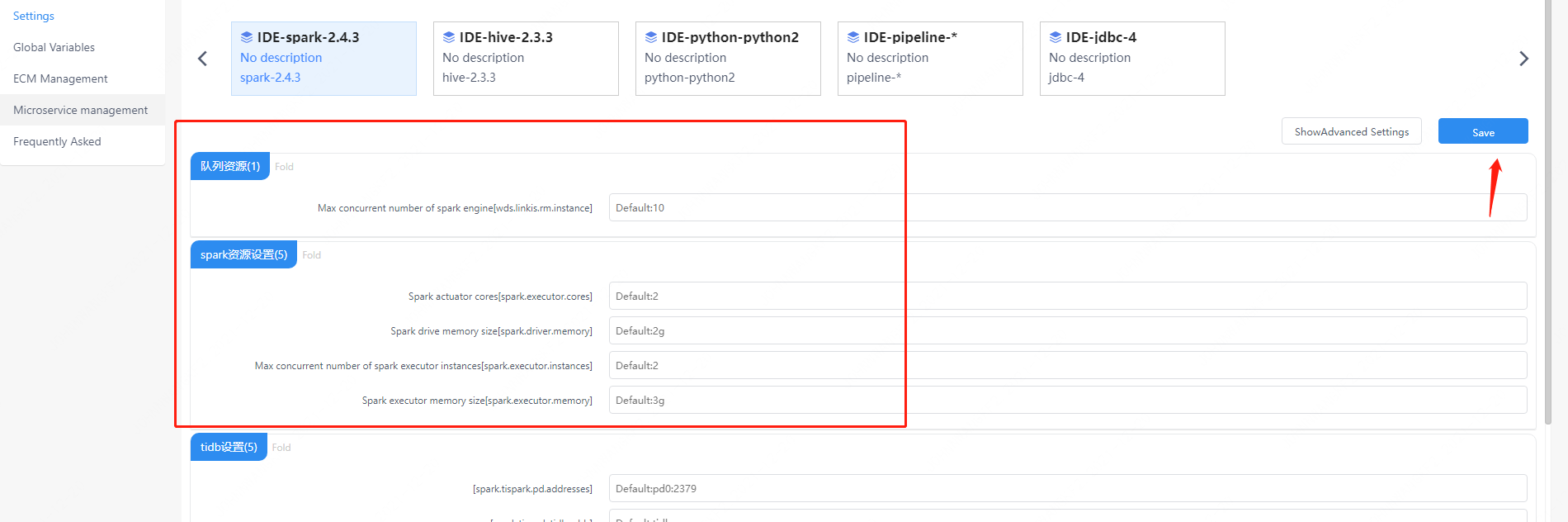
Figure 4-1 Spark user-defined configuration management console