概述
团队有需求要在页面上同时使用sql和python语法对数据进行分析,在调研过程中发现linkis可以满足需要,遂将其引入内网,由于使用的是华为MRS,与开源的软件有所不同, 又进行了二次开发适配,本文将分享使用经验,希望对有需要的同学有所帮助。
环境以及版本
- jdk-1.8.0_112 , maven-3.5.2
- hadoop-3.1.1,Spark-3.1.1,Hive-3.1.0,zookerper-3.5.9 (华为MRS版本)
- linkis-1.3.0
- scriptis-web 1.1.0
依赖调整以及打包
首先从linkis官网上下载1.3.0的源码,然后调整依赖版本
linkis最外层调整pom文件
<hadoop.version>3.1.1</hadoop.version>
<zookerper.version>3.5.9</zookerper.version>
<curaor.version>4.2.0</curaor.version>
<guava.version>30.0-jre</guava.version>
<json4s.version>3.7.0-M5</json4s.version>
<scala.version>2.12.15</scala.version>
<scala.binary.version>2.12</scala.binary.version>
linkis-engineplugin-hive的pom文件
<hive.version>3.1.2</hive.version>
linkis-engineplugin-spark的pom文件
<spark.version>3.1.1</spark.version>
linkis-hadoop-common的pom文件
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId> <!-- 只需要将该行替换即可,替换为 <artifactId>hadoop-hdfs-client</artifactId>-->
<version>${hadoop.version}</version>
</dependency>
将hadoop-hdfs修改为:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
linkis-label-common
org.apache.linkis.manager.label.conf.LabelCommonConfig 修改默认版本,便于后续的自编译调度组件使用
public static final CommonVars<String> SPARK_ENGINE_VERSION =
CommonVars.apply("wds.linkis.spark.engine.version", "3.1.1");
public static final CommonVars<String> HIVE_ENGINE_VERSION =
CommonVars.apply("wds.linkis.hive.engine.version", "3.1.2");
linkis-computation-governance-common
org.apache.linkis.governance.common.conf.GovernanceCommonConf 修改默认版本,便于后续的自编译调度组件使用
val SPARK_ENGINE_VERSION = CommonVars("wds.linkis.spark.engine.version", "3.1.1")
val HIVE_ENGINE_VERSION = CommonVars("wds.linkis.hive.engine.version", "3.1.2")
编译
在以上配置都调整好之后,可以开始全量编译,依次执行以下命令
cd linkis-x.x.x
mvn -N install
mvn clean install -DskipTests
编译错误
- 如果你进行编译的时候,出现了错误,尝试单独进入到一个模块中进行编译,看是否有错误,根据具体的错误来进行调整
- 由于linkis中使用了scala语言进行代码编写,建议可以先在配置scala环境,便于阅读源码
- jar包冲突是最常见的问题,特别是升级了hadoop之后,请耐心调整依赖版本
DataSphereStudio的pom文件
由于我们升级了scala的版本,在部署时会报错,engineplugin启动失败,dss-gateway-support-1.1.0 conn to bml now exit java.net.socketException:Connection reset,这里需要修改scala版本,重新编译。 1.删除掉低版本的 dss-gateway-support jar包, 2.将DSS1.1.0中的scala版本修改为2.12,重新编译,获得新的dss-gateway-support-1.1.0.jar,替换linkis_installhome/lib/linkis-spring-cloud-service/linkis-mg-gateway中原有的jar包
<!-- scala 环境一致 -->
<scala.version>2.12.15</scala.version>
按照上面的依赖版本调整,就能解决大部分问题,如果还有问题则需要对应日志仔细调整。 如果能编译出完整的包,则代表linkis全量编译完成,可以进行部署。
部署
- 为了让引擎节点有足够的资源执行脚本,我们采用了多服务器部署,大致部署结构如下
- SLB 1台 负载均衡为轮询
- ECS-WEB 2台 nginx,静态资源部署,后台代理转发
- ECS-APP 2台 微服务治理,计算治理,公共增强等节点部署
- ECS-APP 4台 EngineConnManager节点部署
linkis部署
- 虽然采用了多节点部署,但是我们并没有将代码剥离,还是把全量包放在服务器上,只是修改了启动脚本,使其只启动所需要的服务
参考官网单机部署示例:https://linkis.apache.org/zh-CN/docs/1.3.0/deployment/deploy-quick
linkis部署注意点
- 1.部署用户: linkis核心进程的启动用户,同时此用户会默认作为管理员权限,部署过程中会生成对应的管理员登录密码,位于conf/linkis-mg-gateway.properties文件中 Linkis支持指定提交、执行的用户。linkis主要进程服务会通过sudo -u ${linkis-user} 切换到对应用户下,然后执行对应的引擎启动命令,所以引擎linkis-engine进程归属的用户是任务的执行者
- 该用户默认为任务的提交和执行者,如果你想改为登录用户,需要修改 org.apache.linkis.entrance.restful.EntranceRestfulApi类下对应提交方法的代码 json.put(TaskConstant.EXECUTE_USER, ModuleUserUtils.getOperationUser(req)); json.put(TaskConstant.SUBMIT_USER, SecurityFilter.getLoginUsername(req)); 将以上设置提交用户和执行用户改为Scriptis页面登录用户
- 2.sudo -u ${linkis-user}切换到对应用户下,如果使用登录用户,这个命令可能会失败,需要修改此处命令。
- org.apache.linkis.ecm.server.operator.EngineConnYarnLogOperator.sudoCommands
private def sudoCommands(creator: String, command: String): Array[String] = {
Array(
"/bin/bash",
"-c",
"sudo su " + creator + " -c \"source ~/.bashrc 2>/dev/null; " + command + "\""
)
} 修改为
private def sudoCommands(creator: String, command: String): Array[String] = {
Array(
"/bin/bash",
"-c",
"\"source ~/.bashrc 2>/dev/null; " + command + "\""
)
}
3.Mysql的驱动包一定要copy到/lib/linkis-commons/public-module/和/lib/linkis-spring-cloud-services/linkis-mg-gateway/
4.默认是使用静态用户和密码,静态用户即部署用户,静态密码会在执行部署是随机生成一个密码串,存储于${LINKIS_HOME}/conf/linkis-mg-gateway.properties
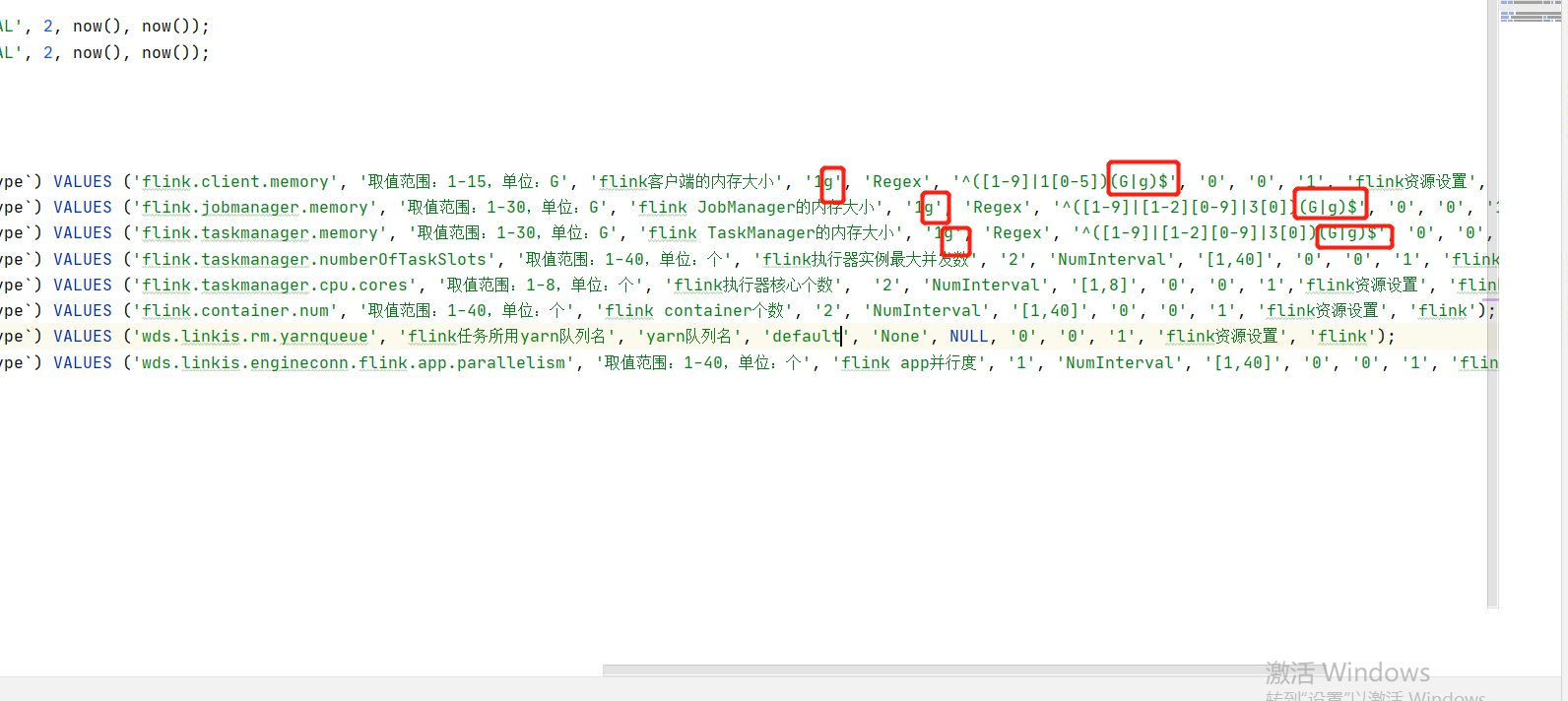
5 数据库脚本执行,linkis本身需要用到数据库,但是我们再执行linkis1.3.0版本的插入数据的脚本时,发现了报错,我们当时时直接删掉了报错部分的数据
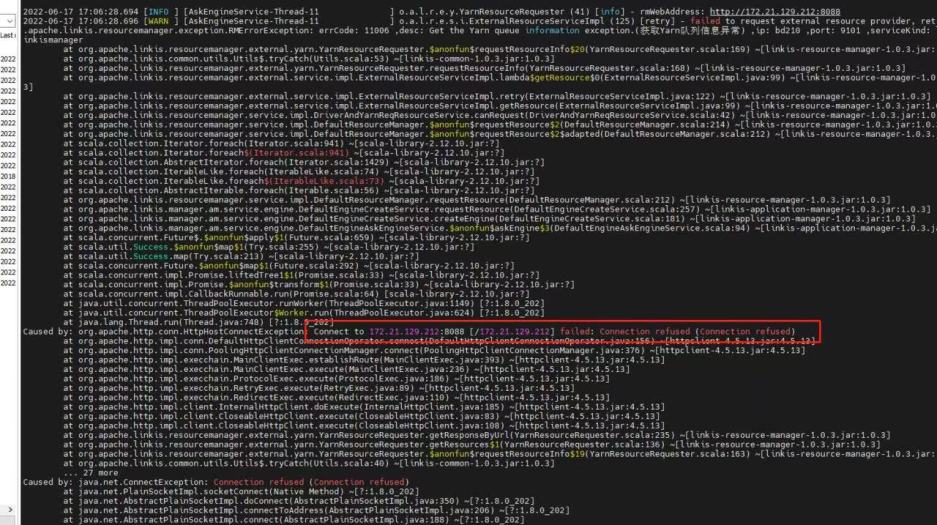
6 Yarn的认证,执行spark任务时会将任务提交到队列上去,会首先获取队列的资源信息,进行判断是否有资源可以提交,这里需要配置是否开启kerberos模式认证和是否使用keytab文件 进行认证,如果开启了文件认证需要将文件放入到服务器对应目录,并且在linkis_cg_rm_external_resource_provider库表中更新信息。
安装web前端
- web端是使用nginx作为静态资源服务器的,直接下载前端安装包并解压,将其放在nginx服务器对应的目录即可
Scriptis工具安装
- scriptis 是一个纯前端的项目,作为一个组件集成在DSS的web代码组件中,我们只需要将DSSweb项目进行单独的scriptis模块编译,将编译的静态资源上传至Linkis管理台所在的服务器,既可访问,注意:linkis单机部署默认使用的是session进行校验,需要先登录linkis管理台,再登录Scriptis就可以使用。
Nginx部署举例
nginx.conf
upstream linkisServer{
server ip:port;
server ip:port;
}
server {
listen 8088;# 访问端口
server_name localhost;
#charset koi8-r;
#access_log /var/log/nginx/host.access.log main;
#scriptis静态资源
location /scriptis {
# 修改为自己的前端路径
alias /home/nginx/scriptis-web/dist; # 静态文件目录
#root /home/hadoop/dss/web/dss/linkis;
index index.html index.html;
}
#默认资源路径指向管理台前端静态资源
location / {
# 修改为自己的前端路径
root /home/nginx/linkis-web/dist; # 静态文件目录
#root /home/hadoop/dss/web/dss/linkis;
index index.html index.html;
}
location /ws {
proxy_pass http://linkisServer/api #后端Linkis的地址
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection upgrade;
}
location /api {
proxy_pass http://linkisServer/api; #后端Linkis的地址
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header x_real_ipP $remote_addr;
proxy_set_header remote_addr $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_http_version 1.1;
proxy_connect_timeout 4s;
proxy_read_timeout 600s;
proxy_send_timeout 12s;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection upgrade;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
}
如何排查问题
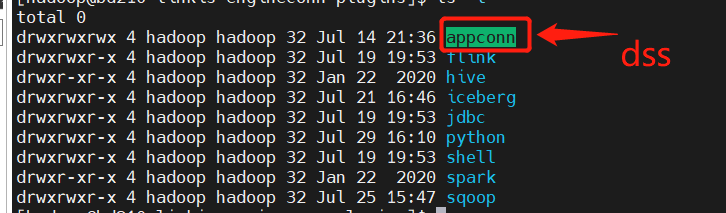
- linkis一共有100多个模块,最终启动的服务一共是7个,分别是 linkis-cg-engineconnmanager,linkis-cg-engineplugin,linkis-cg-entrance,linkis-cg-linkismanager, linkis-mg-gateway, linkis-mg-eureka,linkis-ps-publicservice,每一个模块都有这不同的功能,其中linkis-cg-engineconnmanager 负责管理启动引擎服务,会生成对应引擎的脚本来拉起引擎服务,所以我们团队在部署时将linkis-cg-engineconnmanager单独启动在服务器上以便于有足够的资源给用户执行。
- 像jdbc,spark.hetu之类的引擎的执行需要一些jar包的支撑,在linkis种称之为物料,打包的时候这些jar包会打到linkis-cg-engineplugin下对用的引擎中,会出现conf 和lib目录,启动这个服务时,会将两个打包上传到配置的目录,会生成两个zip文件,我们使用的是OSS来存储这些物料信息,所以首先是上传到OSS,然后再下载到linkis-cg-engineconnmanager这个服务所在服务器上,然后如果配置了以下两个配置 wds.linkis.enginecoon.public.dir 和 wds.linkis.enginecoon.root.dir ,那么会把包拉到wds.linkis.enginecoon.public.dir这个目录下来,wds.linkis.enginecoon.root.dir这个目录是工作目录,里面存放日志和脚本信息,还有一个lib和conf的软连接到 wds.linkis.enginecoon.public.dir。
- 如果要排查引擎日志可以到 wds.linkis.enginecoon.root.dir 配置下的目录去看,当然日志信息也会在Scriptis页面执行的日志上展示,直接粘贴去查找即可。

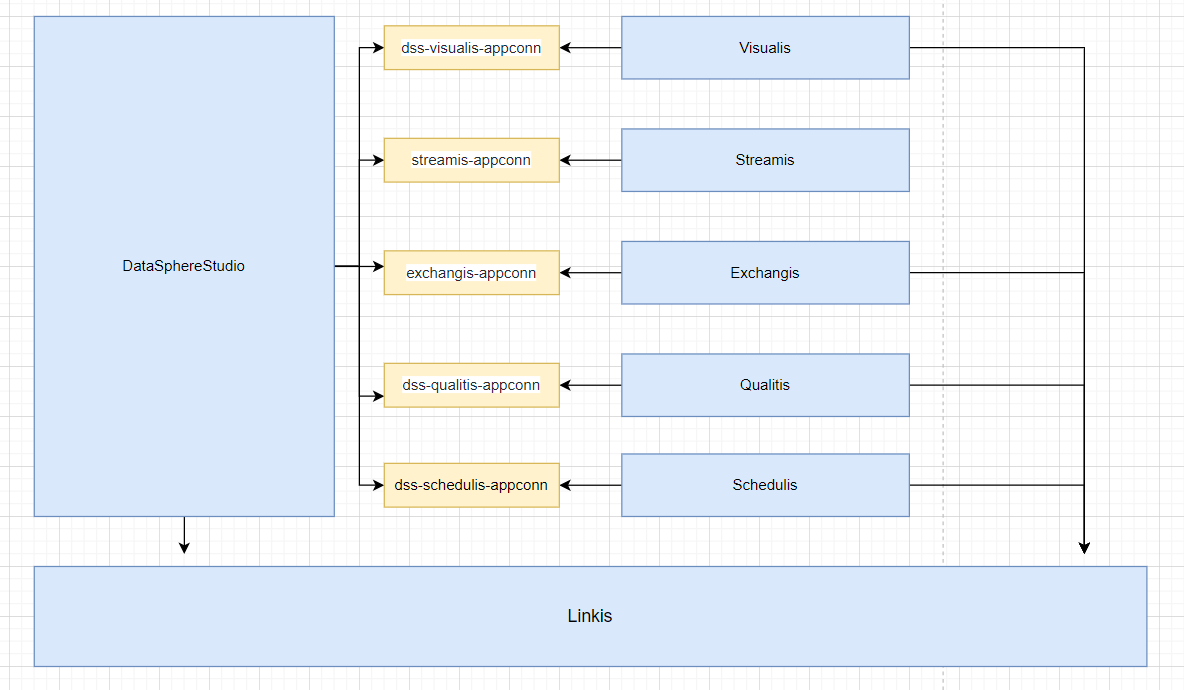
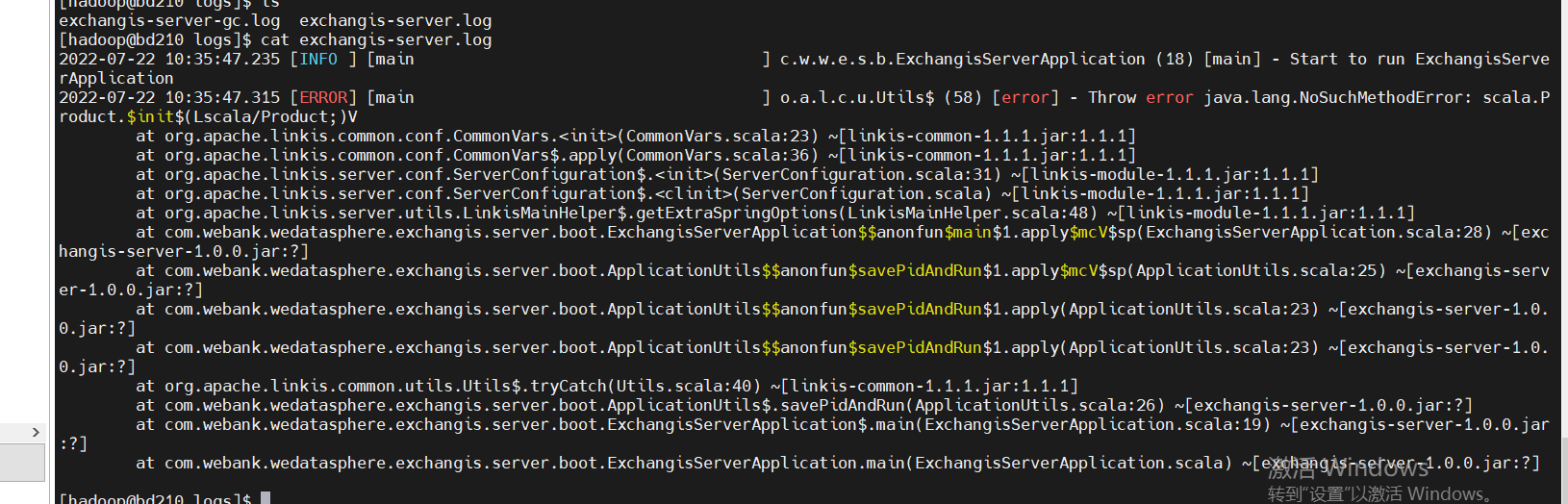
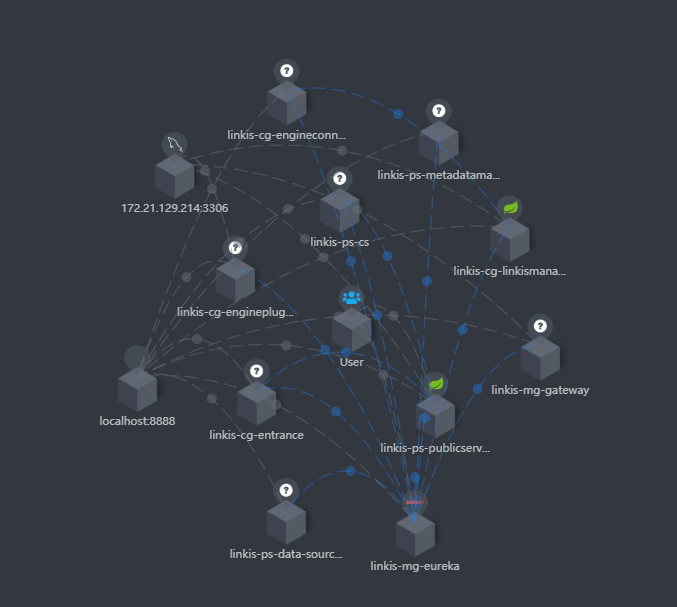 同时你也可以看清晰到在追踪中看到调用链路,如下图,也便于你定位具体服务的错误日志文件
同时你也可以看清晰到在追踪中看到调用链路,如下图,也便于你定位具体服务的错误日志文件

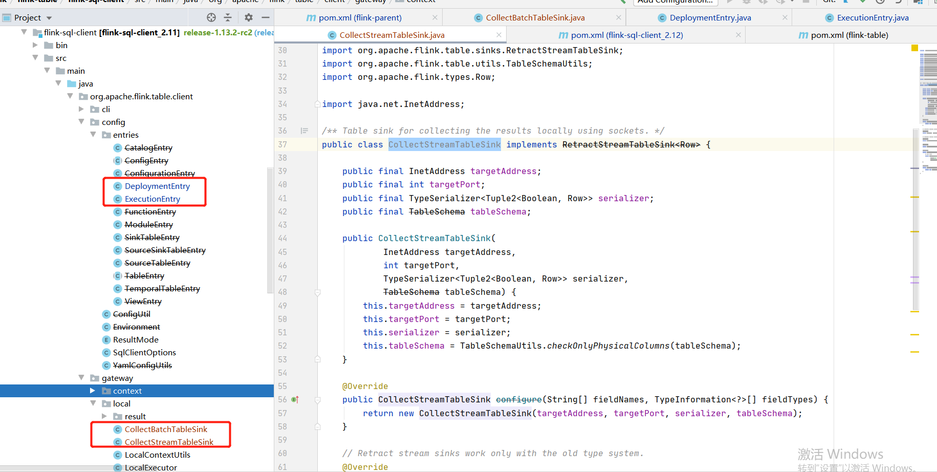
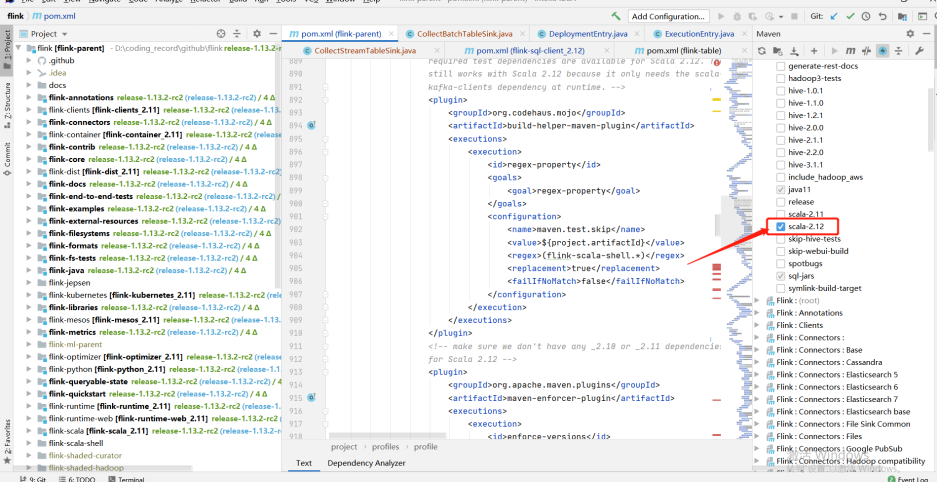
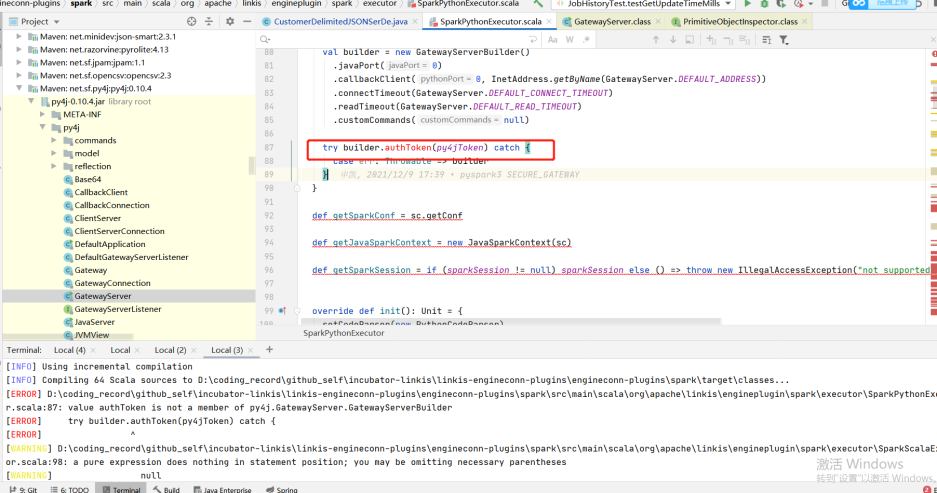


 比如qualitis举例,下面的ip和host端口,根据自己具体使用的来
比如qualitis举例,下面的ip和host端口,根据自己具体使用的来