Spark 引擎
本文主要介绍在Linkis1.X中,spark引擎的配置、部署和使用。
1.Spark引擎使用前的环境配置
如果您希望在您的服务器上使用spark引擎,您需要保证以下的环境变量已经设置正确并且引擎的启动用户是有这些环境变量的。
强烈建议您在执行spark任务之前,检查下执行用户的这些环境变量。
| 环境变量名 | 环境变量内容 | 备注 |
|---|---|---|
| JAVA_HOME | JDK安装路径 | 必须 |
| HADOOP_HOME | Hadoop安装路径 | 必须 |
| HADOOP_CONF_DIR | Hadoop配置路径 | 必须 |
| HIVE_CONF_DIR | Hive配置路径 | 必须 |
| SPARK_HOME | Spark安装路径 | 必须 |
| SPARK_CONF_DIR | Spark配置路径 | 必须 |
| python | python | 建议使用anaconda的python作为默认python |
表1-1 环境配置清单
2.Spark引擎的配置和部署
2.1 spark版本的选择和编译
注意: 编译spark引擎之前需要进行linkis项目全量编译 理论上Linkis1.X支持的spark2.x以上的所有版本。默认支持的版本为Spark2.4.3。如果您想使用其他的spark版本,如spark2.1.0,则您仅仅需要将插件spark的版本进行修改,然后进行编译即可。具体的,您可以找到linkis-engineplugin-spark模块,将maven依赖中"spark.version"标签的值改成2.1.0,然后单独编译此模块即可。
2.2 spark engineConn部署和加载
如果您已经编译完了您的spark引擎的插件,那么您需要将新的插件放置到指定的位置中才能加载,具体可以参考下面这篇文章
2.3 spark引擎的标签
Linkis1.X是通过标签配置来区分引擎版本的,所以需要我们在数据库中插入数据,插入的方式如下文所示。
EngineConnPlugin引擎插件安装 > 2.2 管理台Configuration配置修改(可选)
3.spark引擎的使用
准备操作,队列设置
因为spark的执行需要队列的资源,所以用户在执行之前,必须要设置自己能够执行的队列。
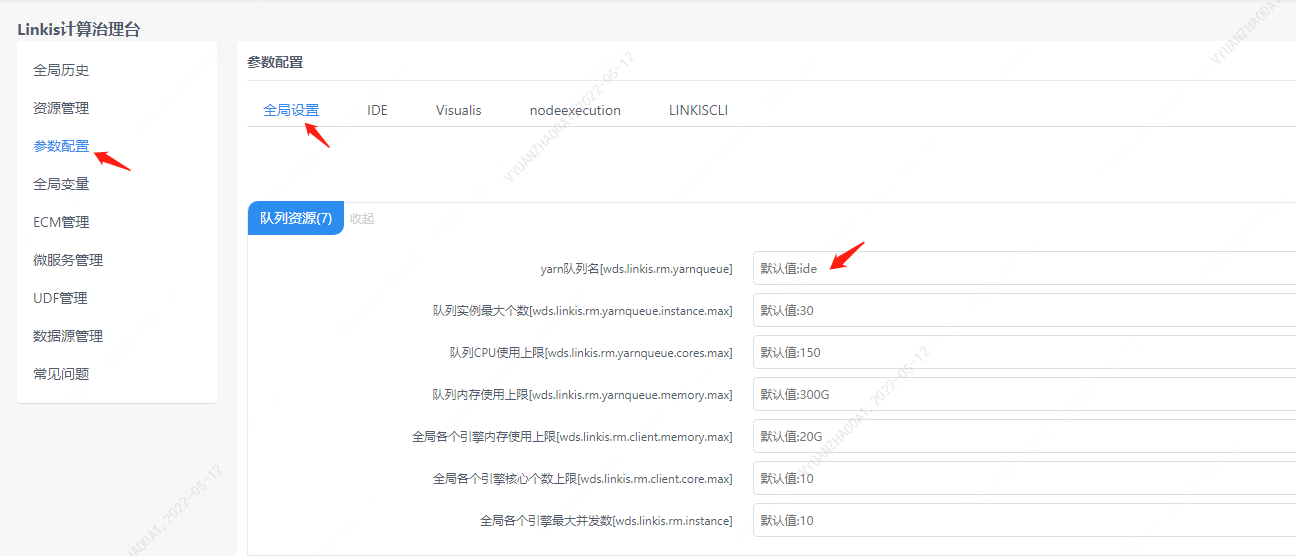
图3-1 队列设置
您也可以通过在提交参数的StartUpMap里面添加队列的值:startupMap.put("wds.linkis.rm.yarnqueue", "dws")
3.1 通过Linkis SDK进行使用
Linkis提供了Java和Scala 的SDK向Linkis服务端提交任务. 具体可以参考 JAVA SDK Manual. 对于Spark任务你只需要修改Demo中的EngineConnType和CodeType参数即可:
Map<String, Object> labels = new HashMap<String, Object>();
labels.put(LabelKeyConstant.ENGINE_TYPE_KEY, "spark-2.4.3"); // required engineType Label
labels.put(LabelKeyConstant.USER_CREATOR_TYPE_KEY, "hadoop-IDE");// required execute user and creator
labels.put(LabelKeyConstant.CODE_TYPE_KEY, "sql"); // required codeType py,sql,scala
3.2 通过Linkis-cli进行任务提交
Linkis 1.0后提供了cli的方式提交任务,我们只需要指定对应的EngineConn和CodeType标签类型即可,Spark的使用如下:
## codeType对应关系 py-->pyspark sql-->sparkSQL scala-->Spark scala
sh ./bin/linkis-cli -engineType spark-2.4.3 -codeType sql -code "show tables" -submitUser hadoop -proxyUser hadoop
# 可以在提交参数通过-confMap wds.linkis.yarnqueue=dws 来指定yarn 队列
sh ./bin/linkis-cli -engineType spark-2.4.3 -codeType sql -confMap wds.linkis.yarnqueue=dws -code "show tables" -submitUser hadoop -proxyUser hadoop
具体使用可以参考: Linkis CLI Manual.
3.3 Scriptis的使用方式
Scriptis的使用方式是最简单的,您可以直接进入Scriptis,新建sql、scala或者pyspark脚本进行执行。
sql的方式是最简单的,您可以新建sql脚本然后编写进行执行,执行的时候,会有进度的显示。如果一开始用户是没有spark引擎的话,sql的执行会启动一个spark会话(这里可能会花一些时间), SparkSession初始化之后,就可以开始执行sql。
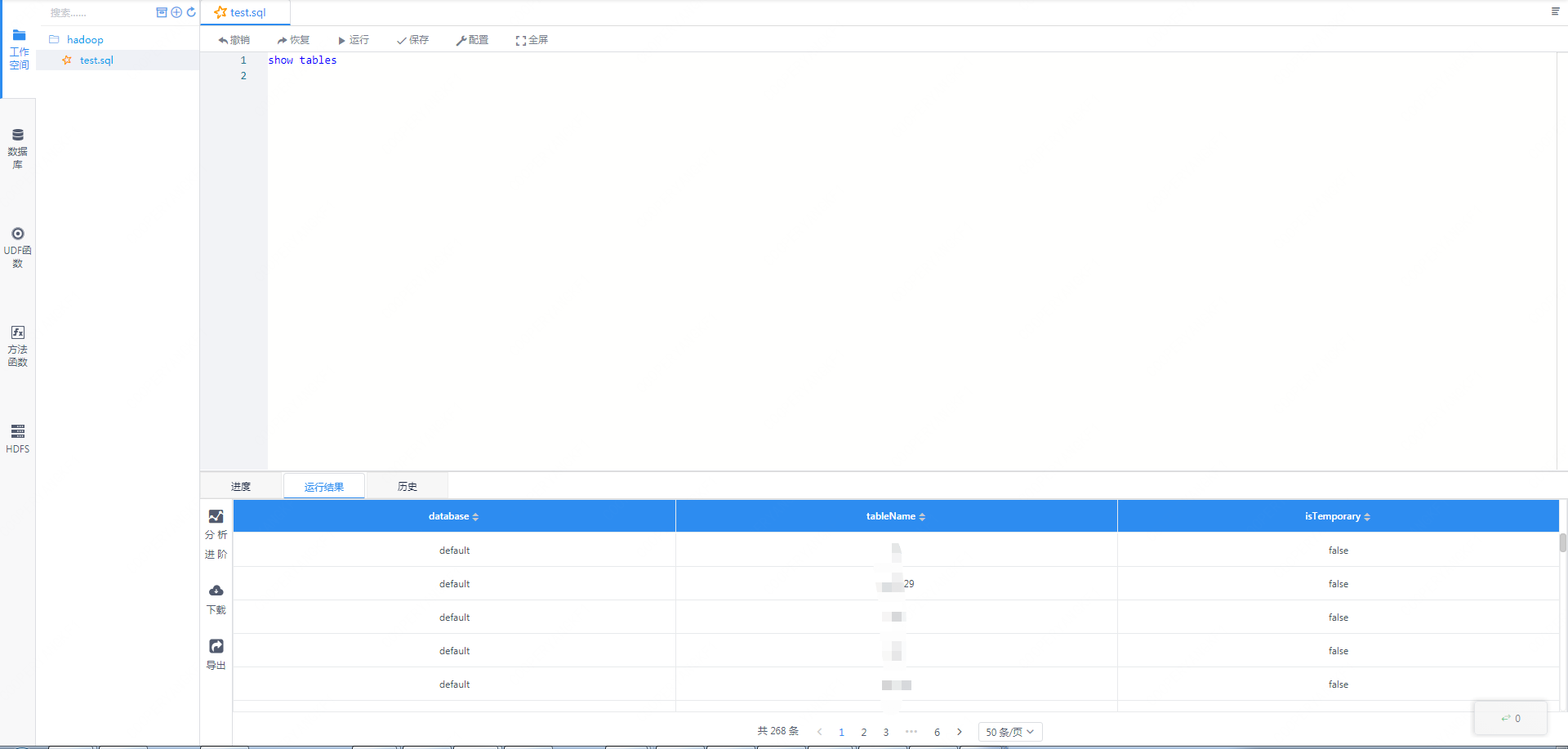
图3-2 sparksql的执行效果截图
spark-scala的任务,我们已经初始化好了sqlContext等变量,用户可以直接使用这个sqlContext进行sql的执行。
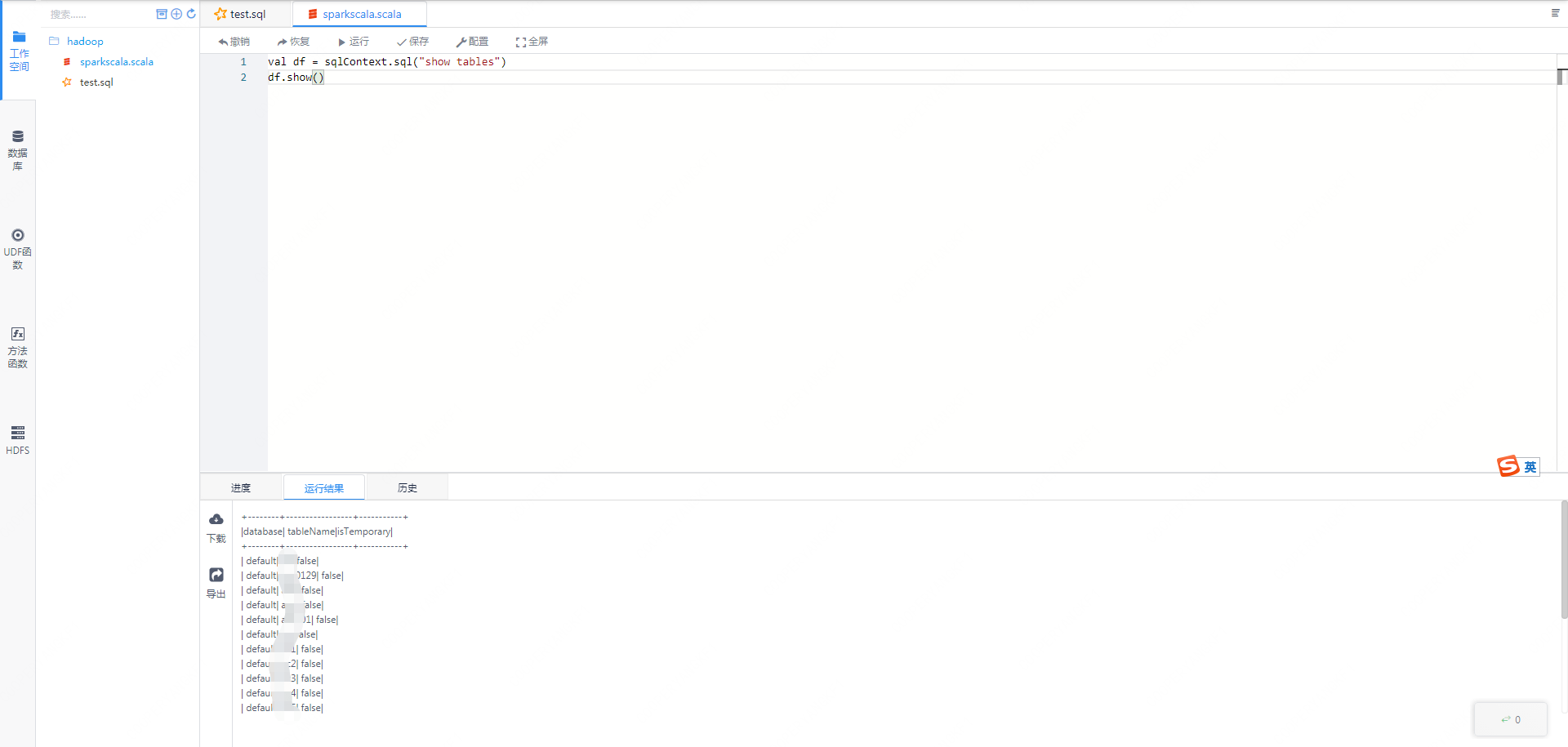
图3-3 spark-scala的执行效果图
类似的,pyspark的方式中,我们也已经初始化好了SparkSession,用户可以直接使用spark.sql的方式进行执行sql。
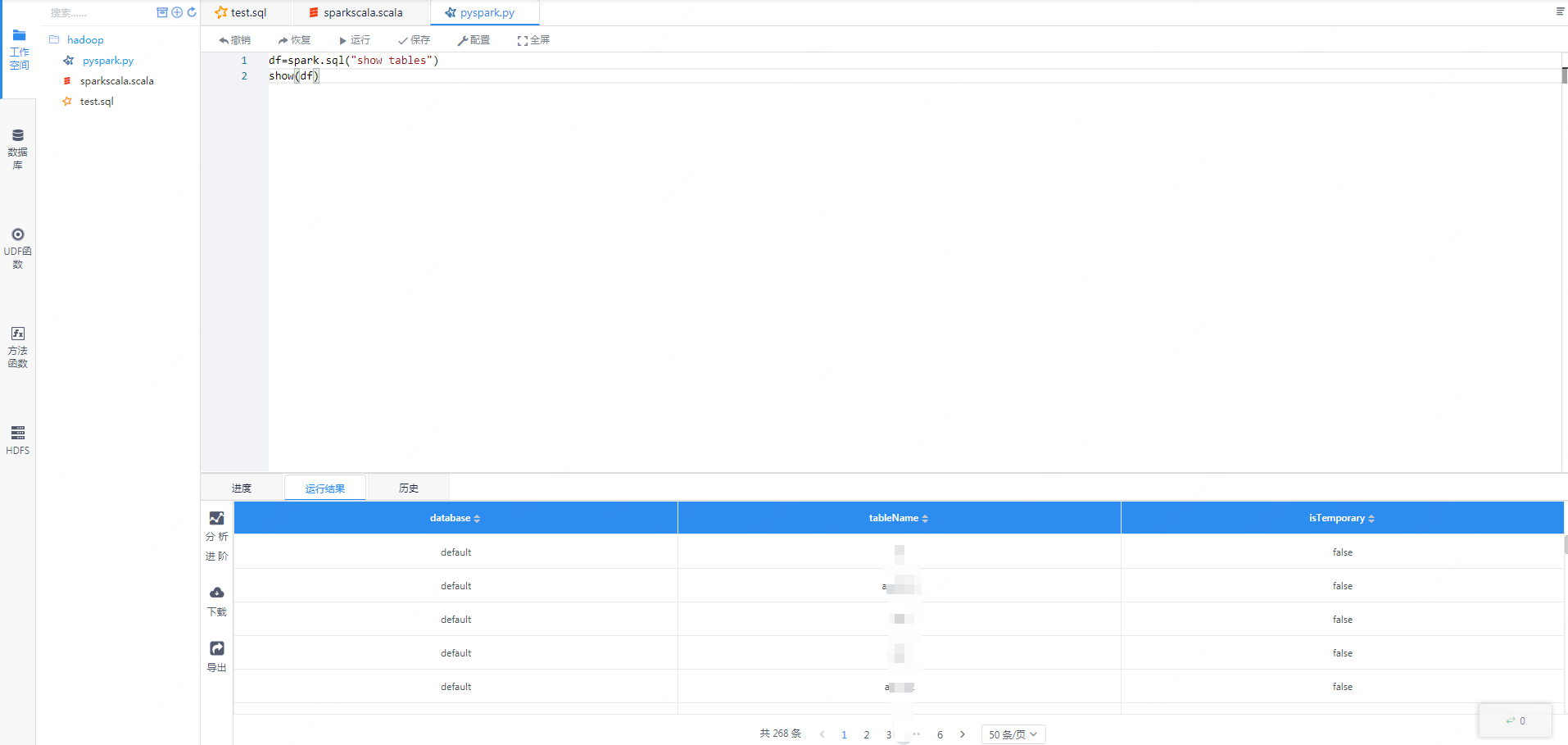 图3-4 pyspark的执行方式
图3-4 pyspark的执行方式
4.spark引擎的用户设置
除了以上引擎配置,用户还可以进行自定义的设置,比如spark会话executor个数和executor的内存。这些参数是为了用户能够更加自由地设置自己的spark的参数,另外spark其他参数也可以进行修改,比如的pyspark的python版本等。
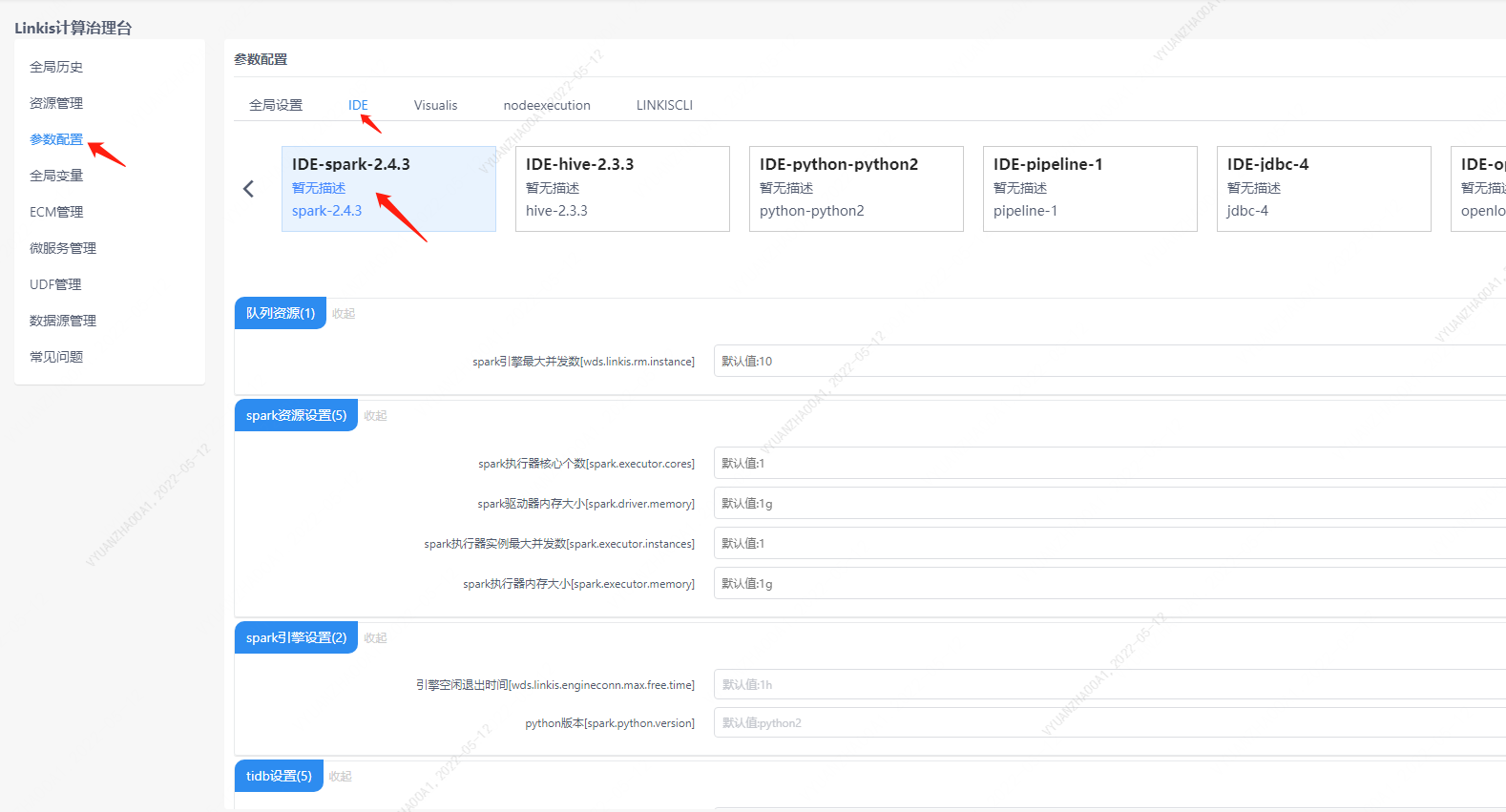
图4-1 spark的用户自定义配置管理台