UDF功能
详细介绍一下如何使用UDF功能
1.UDF创建的整体步骤说明
1 通用类型的UDF函数
整体步骤说明
- 在本地按UDF函数格式 编写udf 函数 ,并打包称jar包文件
- 在【Scriptis >> 工作空间】上传至工作空间对应的目录
- 在 【管理台>>UDF函数】 创建udf (默认加载)
- 在任务代码中使用(对于新起的引擎才生效)
Step1 本地编写jar包
Hive UDF示例:
- 引入 hive 依赖
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.3</version>
</dependency>
- 编写UDF 类
import org.apache.hadoop.hive.ql.exec.UDF;
public class UDFExample extends UDF {
public Integer evaluate(Integer value) {
return value == null ? null : value + 1;
}
}
3. 编译打包
```shell
mvn package
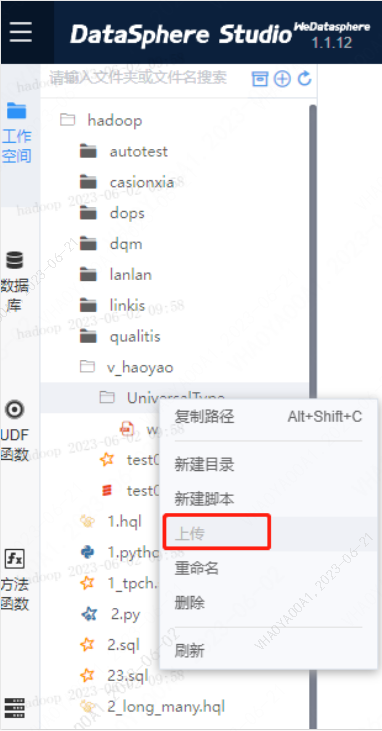
Step2【Scriptis >> 工作空间】上传jar包 选择对应的文件夹 鼠标右键 选择上传
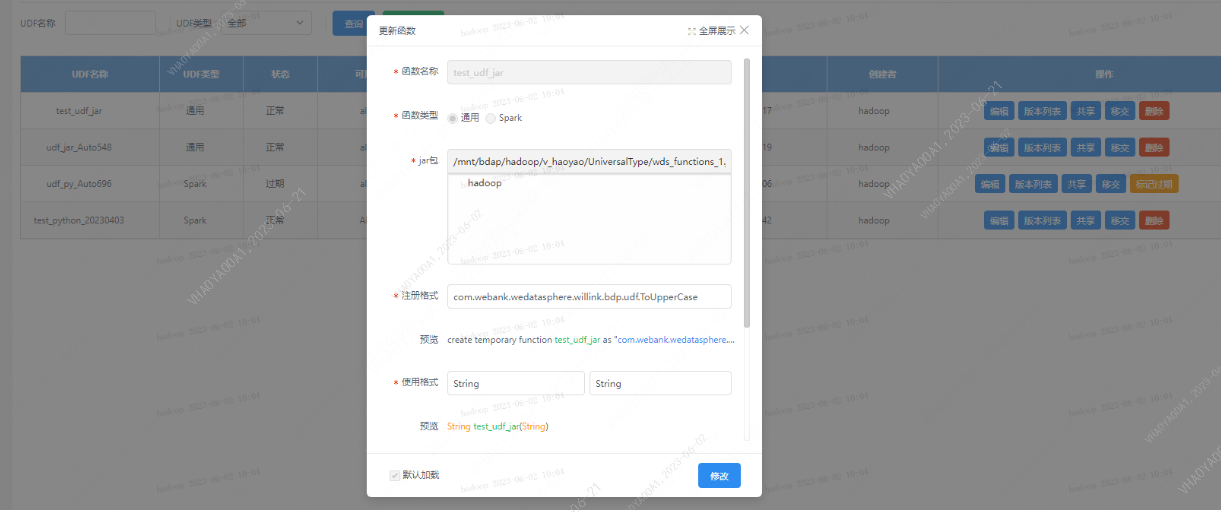
Step3【管理台>>UDF函数】 创建UDF
- 函数名称:符合规则即可,如test_udf_jar 在sql等脚本中使用
- 函数类型:通用
- 脚本路径:选择jar包存放的共享目录路径 如 ../../../wds_functions_1_0_0.jar
- 注册格式:包名+类名,如 com.webank.wedatasphere.willink.bdp.udf.ToUpperCase
- 使用格式:输入类型与返回类型,需与jar包里定义一致
- 分类:下拉选择;或者输入自定义目录(会在个人函数下新建目标一级目录)
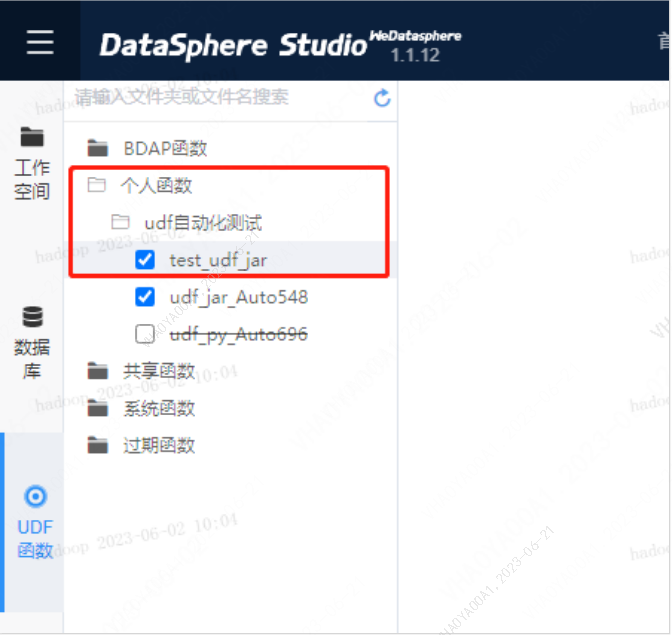
注意 新建的udf 函数 是默认加载的 可以在 【Scriptis >> UDF函数】 页面查看到,方便大家在Scriptis 任务编辑时 方便查看,勾选中的UDF函数 表明是会被加载使用的
Step4 使用该udf函数
在任务中 使用上述步骤创新的udf 函数 函数名为 【创建UDF】 函数名称 在pyspark中: print (sqlContext.sql("select test_udf_jar(name1) from stacyyan_ind.result_sort_1_20200226").collect())
2 Spark类型的UDF函数
整体步骤说明
- 在【Scriptis >> 工作空间】在需要的目录下新建Spark脚本文件
- 在 【管理台>>UDF函数】 创建udf (默认加载)
- 在任务代码中使用(对于新起的引擎才生效)
Step1 dss-scriptis-新建scala脚本
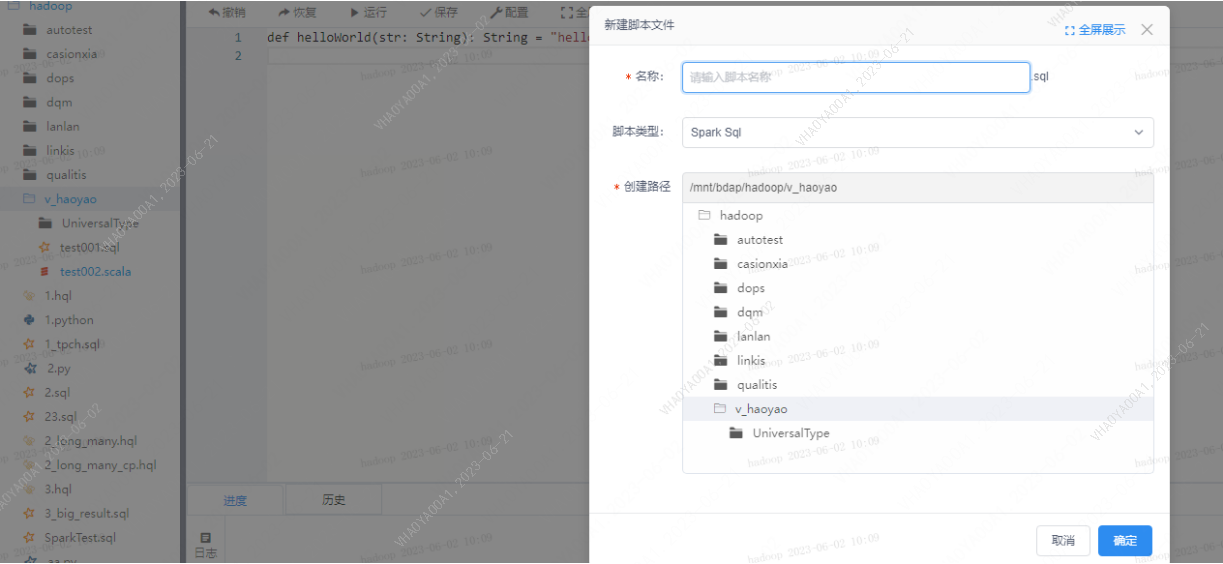
def helloWorld(str: String): String = "hello, " + str
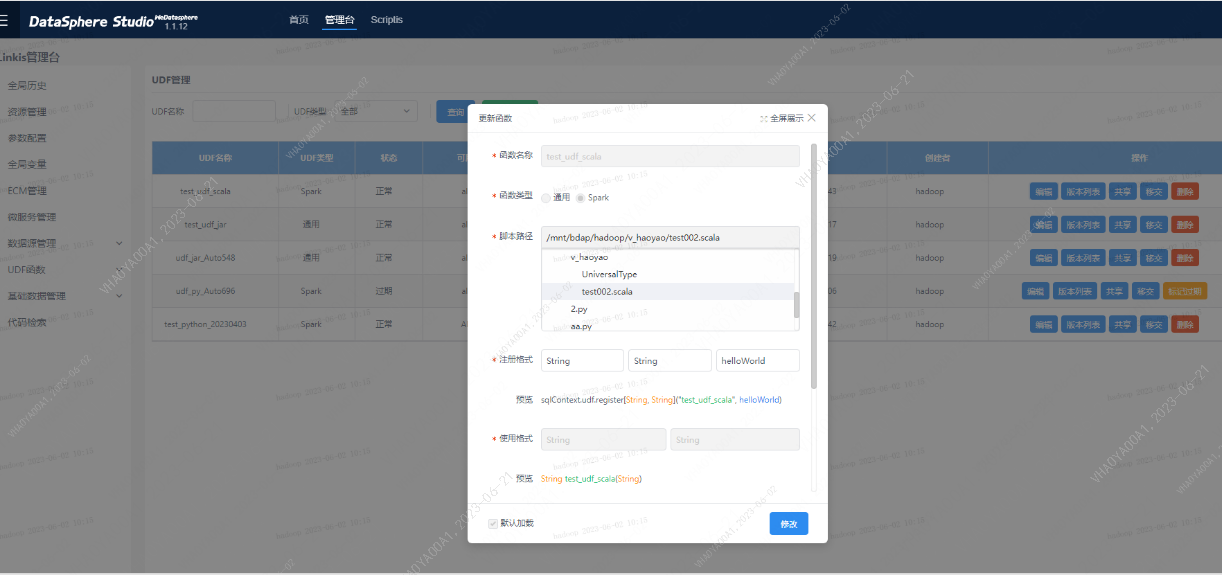
Step2 创建UDF
- 函数名称:符合规则即可,如test_udf_scala
- 函数类型:spark
- 脚本路径:../../../b
- 注册格式:输入类型与返回类型,需与定义一致;注册格式需定义的函数名严格保持一致,如helloWorld
- 分类:下拉选择dss-scriptis-UDF函数-个人函数下存在的一级目录;或者输入自定义目录(会在个人函数下新建目标一级目录)
Step3 使用该udf函数
在任务中 使用上述步骤创建新的udf 函数 函数名为 【创建UDF】 函数名称
- 在scala中 val s=sqlContext.sql("select test_udf_scala(name1) from stacyyan_ind.result_sort_1_20200226") show(s)
- 在pyspark中 print(sqlContext.sql("select test_udf_scala(name1) from stacyyan_ind.result_sort_1_20200226").collect());
- 在sql中 select test_udf_scala(name1) from stacyyan_ind.result_sort_1_20200226;
3 python函数
整体步骤说明
- 在【Scriptis >> 工作空间】在需要的目录下新建Python脚本文件
- 在 【管理台>>UDF函数】 创建udf (默认加载)
- 在任务代码中使用(对于新起的引擎才生效)
Step1 dss-scriptis-新建pyspark脚本
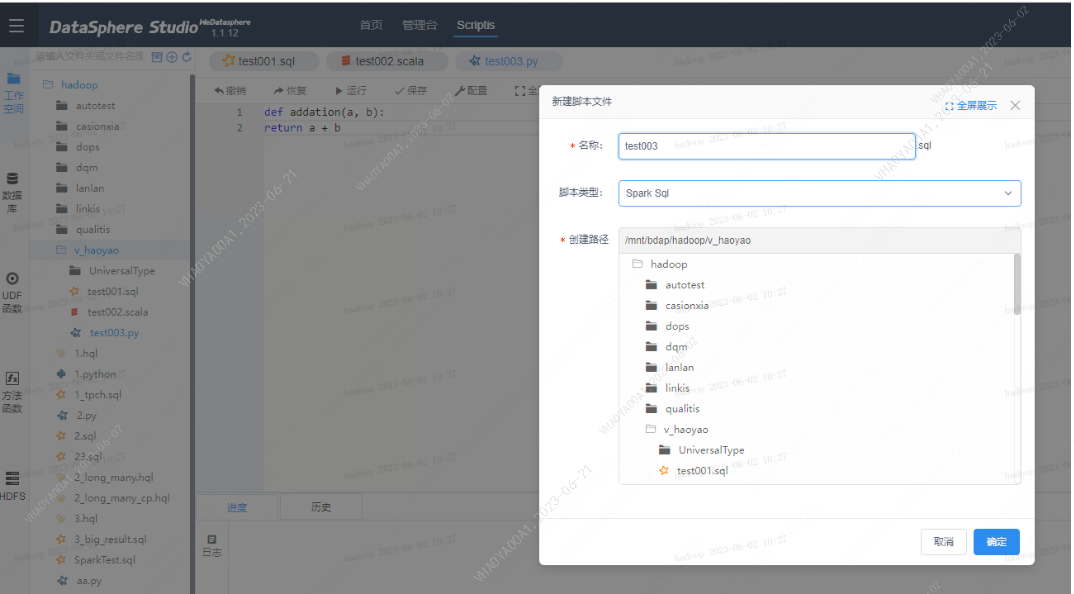
def addation(a, b): return a + b Step2 创建UDF
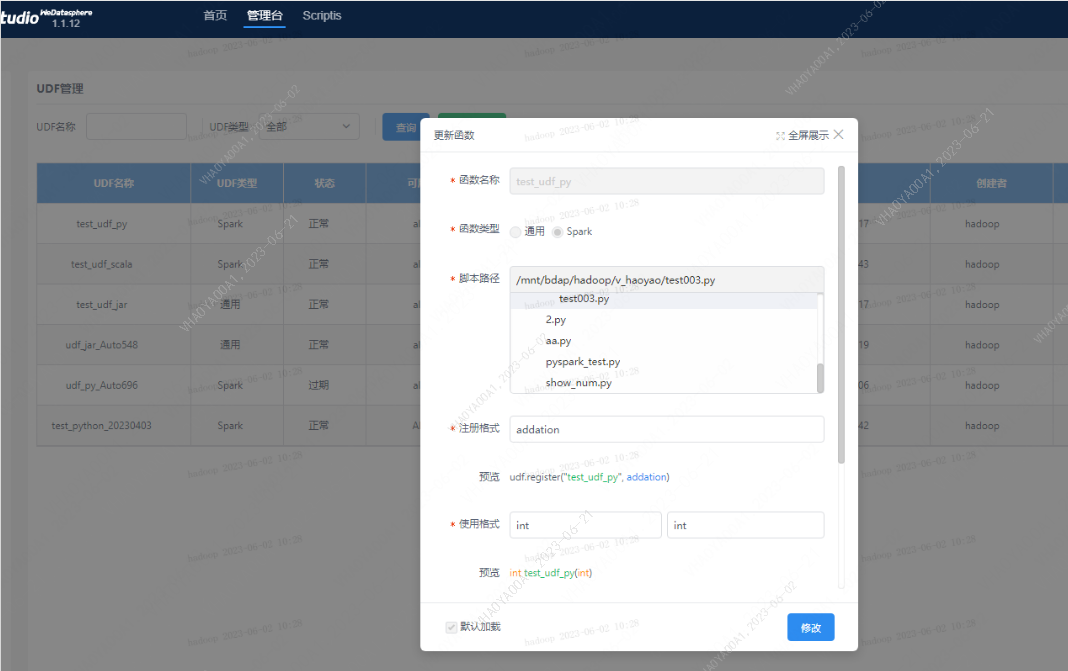
- 函数名称:符合规则即可,如test_udf_py
- 函数类型:spark
- 脚本路径:../../../a
- 注册格式:需定义的函数名严格保持一致,如addation
- 使用格式:输入类型与返回类型,需与定义一致
- 分类:下拉选择dss-scriptis-UDF函数-个人函数下存在的一级目录;或者输入自定义目录(会在个人函数下新建目标一级目录)
Step3 使用该udf函数 在任务中 使用上述步骤创建新的udf 函数 函数名为 【创建UDF】 函数名称
- 在pyspark中 print(sqlContext.sql("select test_udf_py(pv,impression) from neiljianliu_ind.alias where entityid=504059 limit 50").collect());
- 在sql中 select test_udf_py(pv,impression) from neiljianliu_ind.alias where entityid=504059 limit 50
4 scala函数
整体步骤说明
- 在【Scriptis >> 工作空间】在需要的目录下新建Spark Scala脚本文件
- 在 【管理台>>UDF函数】 创建udf (默认加载)
- 在任务代码中使用(对于新起的引擎才生效)
Step1 dss-scriptis-新建scala脚本 def hellozdy(str:String):String = "hellozdy,haha " + str
Step2 创建函数
- 函数名称:需与定义的函数名严格保持一致,如hellozdy
- 函数类型:自定义函数
- 脚本路径:../../../d
- 使用格式:输入类型与返回类型,需与定义一致
- 分类:下拉选择dss-scriptis-方法函数-个人函数下存在的一级目录;或者输入自定义目录(会在个人函数下新建目标一级目录)
Step3 使用该函数 在任务中 使用上述步骤创建新的udf 函数 函数名为 【创建UDF】 函数名称 val a = hellozdy("abcd"); print(a)
5 常见的使用问题
5.1 UDF函数加载失败
"FAILED: SemanticException [Error 10011]: Invalid function xxxx"

首先检查UDF函数配置是否正确:
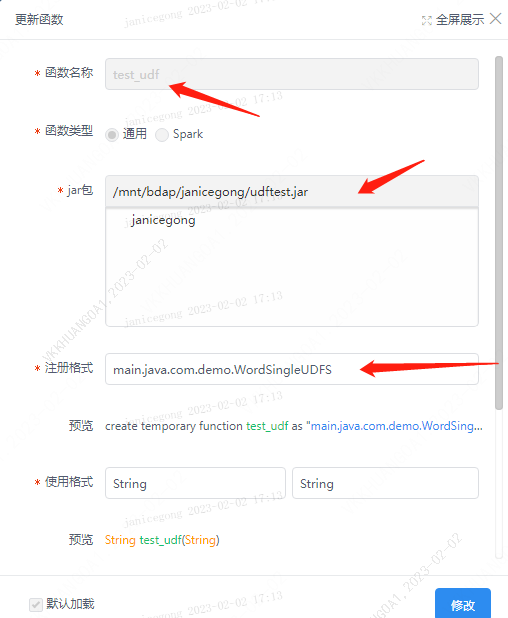
注册格式即为函数路径名称:

检查scriptis-udf函数-查看加载的函数是否勾选,当函数未勾选时,引擎启动时将不会加载udf
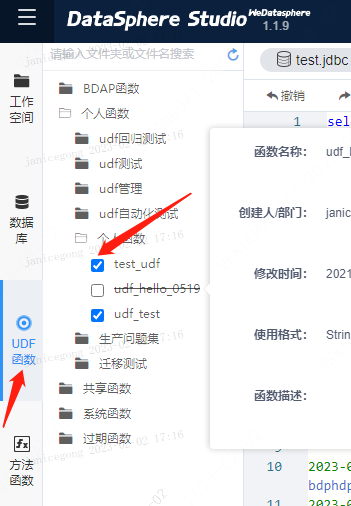
检查引擎是否已加载UDF,如果未加载,请重新另起一个引擎或者重启当前引擎 备注:只有当引擎初始化时,才会加载UDF,中途新增UDF,当前引擎将无法感知并且无法进行加载