总览
背景
什么是上下文Context?
保持某种操作继续进行的所有必需信息。如:同时看三本书,每本书已翻看的页码就是继续看这本书的上下文。
为什么需要CS(Context Service)?
CS,用于解决一个数据应用开发流程,跨多个系统间的数据和信息共享问题。
例如,B系统需要使用A系统产生的一份数据,通常的做法如下:
B系统调用A系统开发的数据访问接口;
B系统读取A系统写入某个共享存储的数据。
有了CS之后,A和B系统只需要与CS交互,将需要共享的数据和信息写入到CS,需要读取的数据和信息从CS中读出即可,无需外部系统两两开发适配,极大降低了系统间信息共享的调用复杂度和耦合度,使各系统的边界更加清晰。
产品范围

元数据上下文
元数据上下文定义元数据规范。
元数据上下文依托于数据中间件,主要功能如下:
打通与数据中间件的关系,能拿到所有的用户元数据信息(包括Hive表元数据、线上库表元数据、其他NOSQL如HBase、Kafka等元数据)
所有节点需要访问元数据时,包括已有元数据和应用模板内元数据,都必须经过元数据上下文。元数据上下文记录了应用模板所使用的所有元数据信息。
各节点所产生的新元数据,都必须往元数据上下文注册。
抽出应用模板时,元数据上下文为应用模板抽象(主要是将用到的多个库表做成\${db}.表形式,避免数据权限问题)和打包所有依赖的元数据信息。
元数据上下文是交互式工作流的基础,也是应用模板的基础。设想:Widget定义时,如何知道DataWrangler定义的各指标维度?Qualitis如何校验Widget产生的图报表?
数据上下文
数据上下文定义数据规范。
数据上下文依赖于数据中间件和Linkis计算中间件。主要功能如下:
打通数据中间件,拿到所有用户数据信息。
打通计算中间件,拿到所有节点的数据存储信息。
所有节点需要写临时结果时,必须通过数据上下文,由数据上下文统一分配。
所有节点需要访问数据时,必须通过数据上下文。
数据上下文会区分依赖数据和生成数据,在抽出应用模板时,为应用模板抽象和打包所有依赖的数据。
资源上下文
资源上下文定义资源规范。
资源上下文主要与Linkis计算中间件交互。主要功能如下:
用户资源文件(如Jar、Zip文件、properties文件等)
用户UDF
用户算法包
用户脚本
环境上下文
环境上下文定义环境规范。
主要功能如下:
操作系统
软件,如Hadoop、Spark等
软件包依赖,如Mysql-JDBC。
对象上下文
运行时上下文为应用模板(工作流)在定义和执行时,所保留的所有上下文信息。
它用于协助定义工作流/应用模板,在工作流/应用模板执行时提示和完善所有必要信息。
运行时工作流主要是Linkis使用。
CS架构图
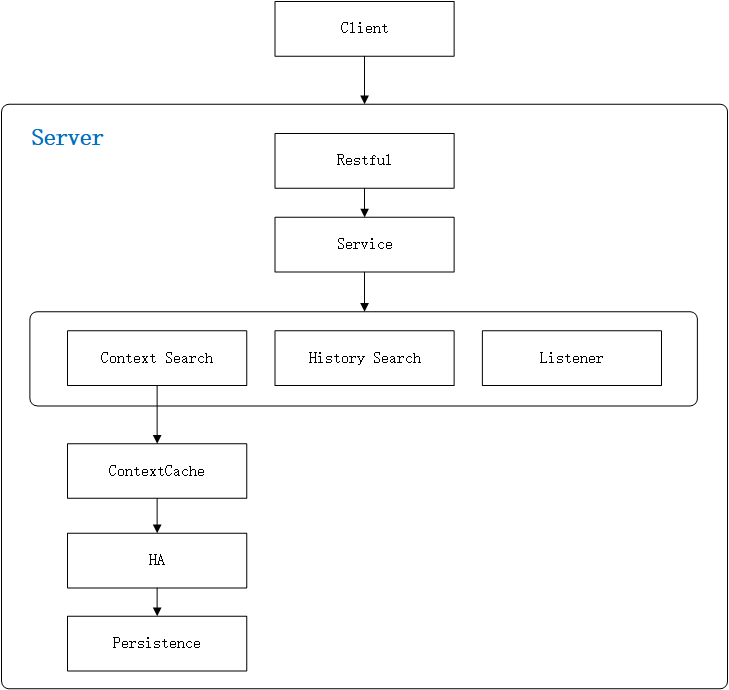
架构说明:
1. Client
外部访问CS的入口,Client模块提供HA功能; 进入Client架构设计
2. Service模块
提供Restful接口,封装和处理客户端提交的CS请求; 进入Service架构设计
3. ContextSearch
上下文查询模块,提供丰富和强大的查询能力,供客户端查找上下文的Key-Value键值对; 进入ContextSearch架构设计
4. Listener
CS的监听器模块,提供同步和异步的事件消费能力,具备类似Zookeeper的Key-Value一旦更新,实时通知Client的能力; 进入Listener架构设计
5. ContextCache
上下文的内存缓存模块,提供快速检索上下文的能力和对JVM内存使用的监听和清理能力; 进入ContextCache架构设计
6. HighAvailable
提供CS高可用能力; 进入HighAvailable架构设计
7. Persistence
CS的持久化功能; 进入Persistence架构设计