Pipeline 引擎
Pipeline的主要用来文件的导入和导出,本文主要介绍
pipeline(>=1.1.0版本支持)引擎的配置、部署和使用。
1. 配置和部署
1.1 引擎包的获取
因为发布的安装部署包中默认安装包中没有pipeline引擎,因此需要获取对应引擎的jar包文件
方式1
通过 非默认引擎物料包 下载
方式2 手动编译获取
注意: 编译pipeline引擎之前需要进行linkis项目全量编译
cd ${linkis_code_dir}
mvn -N install #首次需要进行linkis项目全量编译
cd linkis-enginepconn-pugins/engineconn-plugins/pipeline/
mvn clean install
编译出来的引擎包,位于
${linkis_code_dir}/linkis-engineconn-plugins/pipeline/target/out/pipeline
1.2 物料的部署和加载
将 步骤 1.1获取到的引擎物料包,上传到服务器的引擎目录下${LINKIS_HOME}/lib/linkis-engineplugins
并重启linkis-engineplugin进行引擎刷新
cd ${LINKIS_HOME}/sbin
sh linkis-daemon.sh restart linkis-cg-linkismanager
检查引擎是否刷新成功:可以查看数据库中的linkis_engine_conn_plugin_bml_resources这张表的last_update_time是否为触发刷新的时间。
#登陆到linkis的数据库
select * from linkis_cg_engine_conn_plugin_bml_resources
1.3 引擎的标签(可选)
通过标签来进行的,所以需要在我们数据库中插入数据,插入的方式如下文所示
2. 引擎的使用
因为
pipeline引擎主要用来导入导出文件为主,现在我们假设从A向B导入文件最为介绍案例
2.1 通过Linkis-cli进行任务提交
通过linkis-cli的方式提交任务,需要指定对应的EngineConn和CodeType标签类型,pipeline的使用如下:
- 注意
engineType pipeline-1引擎版本设置是有前缀的 如pipeline版本为v1则设置为pipeline-1
sh bin/linkis-cli -submitUser hadoop -engineType pipeline-1 -codeType pipeline -code "from hdfs:///000/000/000/A.dolphin to file:///000/000/000/B.csv"
from hdfs:///000/000/000/A.dolphin to file:///000/000/000/B.csv 该内容 2.3 有解释
具体使用可以参考: Linkis CLI Manual.
2.2 通过 Scriptis 使用
工作空间模块右键选择新建一个类型为storage的脚本
2.2.1 编写脚本
语法为:from path to path
文件拷贝规则:dolphin后缀类型文件属于结果集文件可转换成.csv类型及.xlsx类型文件,其他类型只能从A地址拷贝到B地址,简称搬运
#dolphin 类型
from hdfs:///000/000/000/A.dolphin to file:///000/000/000/B.csv
from hdfs:///000/000/000/A.dolphin to file:///000/000/000/B.xlsx
#其他类型
from hdfs:///000/000/000/A.txt to file:///000/000/000/B.txt
文件A导出为文件B
from hdfs:///000/000/000/A.csv to file:///000/000/000/B.csv
from path to pathhdfs:///000/000/000/A.csv: 输入文件路径及文件file:///000/000/000/B.csv: 输出文件路径及文件
文件B导出为文件A
from hdfs:///000/000/000/B.csv to file:///000/000/000/A.CSV
hdfs:///000/000/000/B.csv: 输入文件路径及文件file:///000/000/000/A.CSV: 输出文件路径及文件
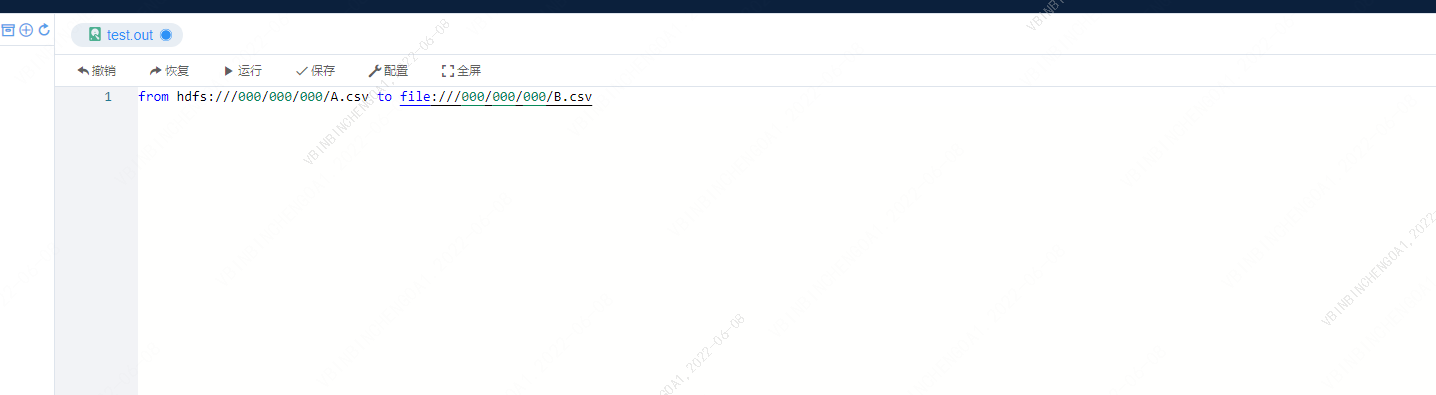
注意:语法末端不能带分号(;),否则语法错误。
2.2.2 结果
进度

历史记录
